Mikroarchitektur
In der Computertechnik ist Mikroarchitektur (manchmal mit µarch oder uarch abgekürzt) eine Beschreibung der elektrischen Schaltungen eines Computers, einer Zentraleinheit oder eines digitalen Signalprozessors, die ausreicht, um die Funktionsweis…
In der Computertechnik ist Mikroarchitektur (manchmal mit µarch oder uarch abgekürzt) eine Beschreibung der elektrischen Schaltungen eines Computers, einer Zentraleinheit oder eines digitalen Signalprozessors, die ausreicht, um die Funktionsweise der Hardware vollständig zu beschreiben.
Gelehrte verwenden den Begriff "Computerorganisation", während Leute in der Computerindustrie häufiger von "Mikroarchitektur" sprechen. Mikroarchitektur und Befehlssatzarchitektur (ISA) bilden zusammen das Gebiet der Computerarchitektur.
Bildergalerie
1 Bild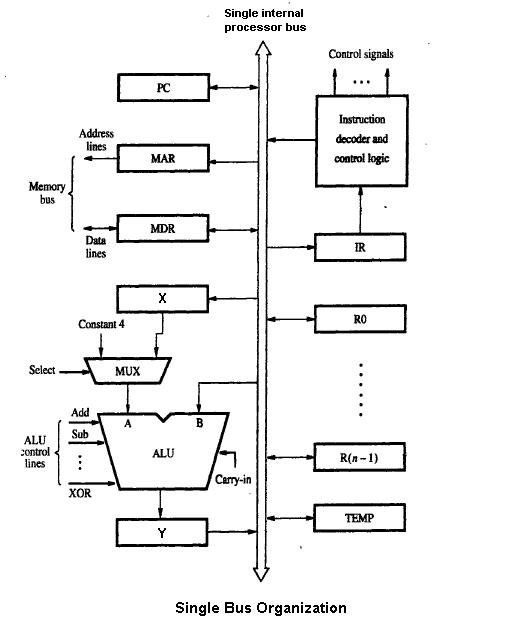
Herkunft des Begriffs
Computer verwenden seit den 1950er Jahren die Mikroprogrammierung von Steuerlogik. Die CPU dekodiert die Befehle und sendet Signale über Transistorschalter auf entsprechenden Pfaden. Die Bits innerhalb der Mikroprogrammwörter steuern den Prozessor auf der Ebene der elektrischen Signale.
Der Begriff: Mikroarchitektur wurde im Gegensatz zum Begriff Mikroarchitektur verwendet, um die Einheiten zu beschreiben, die durch die Mikroprogrammwörter gesteuert wurden: "Architektur", die für Programmierer sichtbar und dokumentiert war. Während die Architektur in der Regel zwischen Hardware-Generationen kompatibel sein musste, konnte die zugrunde liegende Mikroarchitektur leicht verändert werden.
Beziehung zur Befehlssatzarchitektur
Die Mikroarchitektur ist mit der Befehlssatzarchitektur verwandt, aber nicht mit ihr identisch. Die Befehlssatzarchitektur kommt dem Programmiermodell eines Prozessors aus der Sicht eines Assembler-Programmierers oder Compiler-Schreibers nahe, das das Ausführungsmodell, Prozessorregister, Speicheradressmodi, Adress- und Datenformate usw. umfasst. Die Mikroarchitektur (oder Computerorganisation) ist hauptsächlich eine Struktur auf einer niedrigeren Ebene und verwaltet daher eine große Anzahl von Details, die im Programmiermodell verborgen sind. Sie beschreibt die inneren Teile des Prozessors und wie sie zusammenwirken, um die Architekturspezifikation zu implementieren.
Mikroarchitektonische Elemente können alles sein, von einzelnen Logikgattern über Register, Nachschlagetabellen, Multiplexer, Zähler usw. bis hin zu kompletten ALUs, FPUs und sogar größeren Elementen. Die elektronische Schaltungsebene kann wiederum in Details auf Transistorebene unterteilt werden, wie z.B. welche grundlegenden Gate-Aufbaustrukturen verwendet werden und welche Arten der Logikimplementierung (statisch/dynamisch, Anzahl der Phasen usw.) gewählt werden, zusätzlich zu dem tatsächlich verwendeten Logikdesign, mit dem sie aufgebaut wurden.
Ein paar wichtige Punkte:
- Eine einzige Mikroarchitektur, insbesondere wenn sie Mikrocode enthält, kann dazu verwendet werden, viele verschiedene Befehlssätze zu implementieren, indem man den Kontrollspeicher ändert. Dies kann jedoch recht kompliziert sein, selbst wenn es durch Mikrocode und/oder Tabellenstrukturen in ROMs oder PLAs vereinfacht wird.
- Zwei Maschinen können die gleiche Mikroarchitektur und damit das gleiche Blockdiagramm haben, aber völlig unterschiedliche Hardware-Implementierungen. Dadurch wird sowohl die Ebene der elektronischen Schaltungen als auch mehr noch die physikalische Ebene der Fertigung (sowohl der ICs als auch der diskreten Komponenten) verwaltet.
- Maschinen mit unterschiedlichen Mikroarchitekturen können die gleiche Befehlssatzarchitektur haben, so dass beide in der Lage sind, die gleichen Programme auszuführen. Neue Mikroarchitekturen und/oder Schaltungslösungen sowie Fortschritte in der Halbleiterfertigung sind es, die es neueren Prozessorgenerationen ermöglichen, eine höhere Leistung zu erzielen.
Vereinfachte Beschreibungen
Eine sehr vereinfachte Beschreibung auf hoher Ebene - wie sie im Marketing üblich ist - zeigt möglicherweise nur ziemlich grundlegende Merkmale wie Busbreiten sowie verschiedene Arten von Ausführungseinheiten und andere große Systeme wie Zweigprognosen und Cache-Speicher, die als einfache Blöcke dargestellt werden - vielleicht mit einigen wichtigen Attributen oder Merkmalen vermerkt. Einige Details zur Pipelinestruktur (wie Holen, Dekodieren, Zuweisen, Ausführen, Zurückschreiben) können manchmal auch enthalten sein.
Aspekte der Mikroarchitektur
Der Pipeline-Datenpfad ist heute der am häufigsten verwendete Datenpfad in der Mikroarchitektur. Diese Technik wird in den meisten modernen Mikroprozessoren, Mikrocontrollern und DSPs verwendet. Die Pipeline-Architektur ermöglicht es, dass sich mehrere Instruktionen bei der Ausführung überlappen, ähnlich wie bei einem Fließband. Die Pipeline umfasst mehrere verschiedene Stufen, die für das Design von Mikroarchitekturen von grundlegender Bedeutung sind. Einige dieser Stufen umfassen Befehlsabruf, Befehlsdekodierung, Ausführung und Rückschreiben. Einige Architekturen umfassen andere Stufen wie z.B. Speicherzugriff. Der Entwurf von Pipelines ist eine der zentralen Aufgaben der Mikroarchitektur.
Auch Ausführungseinheiten sind für die Mikroarchitektur unerlässlich. Zu den Ausführungseinheiten gehören arithmetische Logikeinheiten (ALU), Gleitkommaeinheiten (FPU), Lade-/Speichereinheiten und Zweigvorhersage. Diese Einheiten führen die Operationen oder Berechnungen des Prozessors aus. Die Wahl der Anzahl der Ausführungseinheiten, ihre Latenz und ihr Durchsatz sind wichtige Entwurfsaufgaben der Mikroarchitektur. Die Größe, Latenz, Durchsatz und Konnektivität der Speicher innerhalb des Systems sind ebenfalls Entscheidungen der Mikroarchitektur.
Design-Entscheidungen auf Systemebene, z.B. ob Peripheriegeräte wie Speicher-Controller einbezogen werden sollen oder nicht, können als Teil des mikroarchitektonischen Designprozesses betrachtet werden. Dazu gehören Entscheidungen über die Leistungsebene und die Konnektivität dieser Peripheriegeräte.
Im Gegensatz zum architektonischen Design, bei dem ein bestimmtes Leistungsniveau das Hauptziel ist, wird beim mikro-architektonischen Design stärker auf andere Einschränkungen geachtet. Aufmerksamkeit muss unter anderem folgenden Aspekten gewidmet werden
- Chipfläche/Kosten.
- Leistungsaufnahme.
- Komplexität der Logik.
- Leichte Konnektivität.
- Herstellbarkeit.
- Leichte Fehlersuche.
- Testbarkeit.
Mikro-architektonische Konzepte
Im Allgemeinen führen alle CPUs, Single-Chip-Mikroprozessoren oder Multi-Chip-Implementierungen Programme aus, indem sie die folgenden Schritte ausführen:
- Lesen Sie eine Anweisung und entschlüsseln Sie sie.
- Suchen Sie alle zugehörigen Daten, die zur Verarbeitung der Anweisung benötigt werden.
- Verarbeiten Sie die Anweisung.
- Schreiben Sie die Ergebnisse aus.
Kompliziert wird diese einfach aussehende Reihe von Schritten durch die Tatsache, dass die Speicherhierarchie, die Caching, Hauptspeicher und nichtflüchtige Speicher wie Festplatten (auf denen sich die Programmbefehle und Daten befinden) umfasst, schon immer langsamer war als der Prozessor selbst. Schritt (2) führt oft zu einer Verzögerung (in CPU-Ausdrücken oft als "Stillstand" bezeichnet), während die Daten über den Computerbus ankommen. Es wurde viel Forschungsarbeit in Designs investiert, die diese Verzögerungen so weit wie möglich vermeiden. Im Laufe der Jahre war es ein zentrales Entwurfsziel, mehr Anweisungen parallel auszuführen und so die effektive Ausführungsgeschwindigkeit eines Programms zu erhöhen. Diese Bemühungen führten zu komplizierten Logik- und Schaltungsstrukturen. In der Vergangenheit konnten solche Techniken aufgrund des für diese Techniken erforderlichen Schaltungsaufwands nur auf teuren Großrechnern oder Supercomputern implementiert werden. Mit fortschreitender Halbleiterfertigung konnten immer mehr dieser Techniken auf einem einzigen Halbleiterchip implementiert werden.
Im Folgenden wird ein Überblick über Mikroarchitekturtechniken gegeben, die in modernen CPUs üblich sind.
Auswahl des Instruktionssatzes
Die Wahl der zu verwendenden Befehlssatzarchitektur hat großen Einfluss auf die Komplexität der Implementierung von Hochleistungsgeräten. Im Laufe der Jahre taten die Computerdesigner ihr Bestes, um die Befehlssätze zu vereinfachen, um leistungsfähigere Implementierungen zu ermöglichen, indem sie den Designern Aufwand und Zeit für Funktionen ersparten, die die Leistung verbessern, anstatt sie an die Komplexität des Befehlssatzes zu verschwenden.
Die Entwicklung von Befehlssätzen hat sich von den CISC-, RISC-, VLIW- und EPIC-Typen weiterentwickelt. Zu den Architekturen, die sich mit Datenparallelität befassen, gehören SIMD und Vektoren.
Befehls-Pipelining
Eine der ersten und leistungsfähigsten Techniken zur Leistungsverbesserung ist die Verwendung der Befehlspipeline. Frühe Prozessorentwürfe führten alle oben genannten Schritte bei einer Anweisung aus, bevor sie zur nächsten übergingen. Große Teile des Prozessorkreislaufs wurden bei jedem Schritt untätig gelassen; zum Beispiel war der Schaltkreis für die Befehlsdekodierung während der Ausführung untätig und so weiter.
Pipelines verbessern die Leistung, indem sie es ermöglichen, dass eine Reihe von Anweisungen gleichzeitig durch den Prozessor arbeiten. Im gleichen grundlegenden Beispiel würde der Prozessor mit der Dekodierung (Schritt 1) einer neuen Anweisung beginnen, während die letzte auf Ergebnisse wartet. Auf diese Weise könnten bis zu vier Befehle gleichzeitig "im Flug" sein, wodurch der Prozessor viermal so schnell aussehen würde. Obwohl die Ausführung einer einzelnen Anweisung genauso lange dauert (es gibt immer noch vier Schritte), "pensioniert" die CPU als Ganzes die Anweisungen viel schneller und kann mit einer viel höheren Taktgeschwindigkeit ausgeführt werden.
Cache
Verbesserungen in der Chipherstellung ermöglichten es, mehr Schaltkreise auf demselben Chip zu platzieren, und die Designer begannen nach Wegen zu suchen, diese zu nutzen. Eine der gängigsten Methoden war das Hinzufügen einer immer größeren Menge an Cache-Speicher auf dem Chip. Cache ist ein sehr schneller Speicher, auf den in wenigen Zyklen zugegriffen werden kann, im Vergleich zu dem, was benötigt wird, um mit dem Hauptspeicher zu kommunizieren. Die CPU enthält einen Cache-Controller, der das Lesen und Schreiben aus dem Cache automatisiert. Wenn sich die Daten bereits im Cache befinden, "erscheinen" sie einfach, wenn sie nicht im Cache sind, wird der Prozessor "angehalten", während der Cache-Controller sie einliest.
RISC-Designs begannen Mitte bis Ende der 1980er Jahre mit dem Hinzufügen von Cache, oft nur 4 KB insgesamt. Diese Zahl wuchs im Laufe der Zeit, und typische CPUs haben heute etwa 512 KB, während leistungsfähigere CPUs mit 1 oder 2 oder sogar 4, 6, 8 oder 12 MB kommen, die in mehreren Ebenen einer Speicherhierarchie organisiert sind. Allgemein gesagt, mehr Cache bedeutet mehr Geschwindigkeit.
Caches und Pipelines passten perfekt zueinander. Früher machte es nicht viel Sinn, eine Pipeline aufzubauen, die schneller laufen konnte als die Zugriffslatenz des Off-Chip-Bargeldspeichers. Die Verwendung von On-Chip-Cache-Speicher bedeutete stattdessen, dass eine Pipeline mit der Geschwindigkeit der Cache-Zugriffslatenz laufen konnte, d.h. mit einer viel geringeren Zeitspanne. Dadurch konnten die Betriebsfrequenzen der Prozessoren viel schneller steigen als die des Off-Chip-Speichers.
Zweigprognose und spekulative Ausführung
Pipelinestillstände und Spülungen aufgrund von Abzweigungen sind die beiden wichtigsten Dinge, die verhindern, dass durch Parallelität auf Anweisungsebene eine höhere Leistung erzielt werden kann. Von dem Zeitpunkt, an dem der Befehlsdecoder des Prozessors festgestellt hat, dass er auf einen bedingten Verzweigungsbefehl gestoßen ist, bis zu dem Zeitpunkt, an dem der entscheidende Sprungregisterwert ausgelesen werden kann, kann die Pipeline für mehrere Zyklen blockiert sein. Im Durchschnitt ist jeder fünfte ausgeführte Befehl ein Zweig, so dass die Pipeline in hohem Maße blockiert ist. Wenn die Verzweigung genommen wird, ist es noch schlimmer, da dann alle nachfolgenden Befehle, die in der Pipeline waren, gespült werden müssen.
Techniken wie die Zweigprognose und die spekulative Ausführung werden eingesetzt, um diese Zweigstrafen zu reduzieren. Bei der Zweigprognose macht die Hardware fundierte Vermutungen darüber, ob ein bestimmter Zweig genommen wird. Durch die Vermutung kann die Hardware Anweisungen vorab abrufen, ohne auf das Lesen des Registers zu warten. Die spekulative Ausführung ist eine weitere Verbesserung, bei der der Code entlang des vorhergesagten Pfades ausgeführt wird, bevor bekannt ist, ob die Verzweigung genommen werden soll oder nicht.
Ausführung außerhalb der Reihenfolge
Die Hinzufügung von Caches verringert die Häufigkeit oder Dauer von Datenstaus, die durch das Warten auf den Abruf von Daten aus der Hauptspeicherhierarchie verursacht werden, beseitigt diese Datenstaus aber nicht vollständig. In frühen Entwürfen würde ein Cache-Miss den Cache-Controller zwingen, den Prozessor zum Stillstand zu bringen und zu warten. Natürlich kann es auch eine andere Anweisung im Programm geben, deren Daten zu diesem Zeitpunkt im Cache verfügbar sind. Bei der Ausführung in der falschen Reihenfolge kann diese fertige Anweisung verarbeitet werden, während eine ältere Anweisung im Cache wartet und dann die Ergebnisse neu anordnet, um den Anschein zu erwecken, dass alles in der programmierten Reihenfolge geschehen ist.
Superskala
Selbst bei all der zusätzlichen Komplexität und den Gates, die zur Unterstützung der oben skizzierten Konzepte erforderlich sind, ermöglichten Verbesserungen in der Halbleiterfertigung bald den Einsatz von noch mehr Logikgattern.
In der obigen Skizze verarbeitet der Prozessor Teile einer einzelnen Anweisung auf einmal. Computerprogramme könnten schneller ausgeführt werden, wenn mehrere Befehle gleichzeitig verarbeitet würden. Genau das erreichen superskalare Prozessoren, indem sie Funktionseinheiten wie ALUs replizieren. Die Replikation von Funktionseinheiten wurde erst möglich, als der Bereich der integrierten Schaltung (manchmal auch als "Die" bezeichnet) eines Single-Image-Prozessors die Grenzen dessen, was zuverlässig hergestellt werden konnte, nicht mehr überschritt. In den späten 1980er Jahren begannen superskalare Designs auf den Markt zu kommen.
In modernen Designs ist es üblich, zwei Ladeeinheiten, einen Speicher (viele Anweisungen haben keine Ergebnisse zu speichern), zwei oder mehr ganzzahlige mathematische Einheiten, zwei oder mehr Gleitkommaeinheiten und oft eine Art SIMD-Einheit zu finden. Die Befehlsausgabelogik wird immer komplexer, indem eine riesige Liste von Befehlen aus dem Speicher eingelesen und an die verschiedenen Ausführungseinheiten übergeben wird, die zu diesem Zeitpunkt untätig sind. Die Ergebnisse werden dann gesammelt und am Ende neu geordnet.
Register-Umbenennung
Die Umbenennung von Registern bezieht sich auf eine Technik, mit der eine unnötige serialisierte Ausführung von Programmbefehlen aufgrund der Wiederverwendung derselben Register durch diese Befehle vermieden wird. Angenommen, wir haben es mit Gruppen von Befehlen zu tun, die dasselbe Register verwenden, dann wird ein Befehlssatz zuerst ausgeführt, um das Register dem anderen Satz zu überlassen, aber wenn der andere Satz einem anderen ähnlichen Register zugeordnet ist, können beide Befehlssätze parallel ausgeführt werden.
Multiprocessing und Multithreading
Aufgrund der wachsenden Kluft zwischen den CPU-Betriebsfrequenzen und den DRAM-Zugriffszeiten konnte keine der Techniken, die die Parallelität auf Befehlsebene (ILP) innerhalb eines Programms verbessern, die langen Stillstände (Verzögerungen) überwinden, die auftraten, wenn Daten aus dem Hauptspeicher geholt werden mussten. Darüber hinaus erforderten die großen Transistorzahlen und hohen Betriebsfrequenzen, die für die fortgeschritteneren ILP-Techniken erforderlich sind, Verlustleistungspegel, die nicht mehr billig gekühlt werden konnten. Aus diesen Gründen haben neuere Computergenerationen begonnen, höhere Parallelitätsebenen zu nutzen, die außerhalb eines einzelnen Programms oder Programm-Threads existieren.
Dieser Trend wird manchmal als "Throughput Computing" bezeichnet. Diese Idee stammt aus dem Mainframe-Markt, wo bei der Online-Transaktionsverarbeitung nicht nur die Ausführungsgeschwindigkeit einer Transaktion im Vordergrund stand, sondern auch die Fähigkeit, eine große Anzahl von Transaktionen gleichzeitig zu bewältigen. Da transaktionsbasierte Anwendungen wie Netzwerk-Routing und Website-Bedienung in den letzten zehn Jahren stark zugenommen haben, hat die Computerindustrie die Kapazitäts- und Durchsatzprobleme wieder stärker in den Vordergrund gerückt.
Eine Technik, wie diese Parallelität erreicht wird, sind Multiprozessorsysteme, Computersysteme mit mehreren CPUs. In der Vergangenheit war dies den High-End-Großrechnern vorbehalten, aber jetzt sind Multiprozessor-Server im kleinen Maßstab (2-8) für den Markt der Kleinunternehmen alltäglich geworden. Für große Unternehmen sind große (16-256) Multiprozessoren üblich. Seit den 1990er Jahren sind sogar Personalcomputer mit mehreren CPUs aufgetaucht.
Fortschritte in der Halbleitertechnologie haben die Größe der Transistoren verringert; es sind Mehrkern-CPUs erschienen, bei denen mehrere CPUs auf demselben Siliziumchip implementiert sind. Ursprünglich wurden In-Chips verwendet, die auf eingebettete Märkte abzielten, wo einfachere und kleinere CPUs es ermöglichen würden, dass mehrere Instanzen auf ein Stück Silizium passen. Bis 2005 ermöglichte es die Halbleitertechnologie, CMP-Chips mit zwei High-End-Desktop-CPUs in Serie herzustellen. Einige Designs, wie z.B. UltraSPARC T1, benutzten einfachere (skalare, geordnete) Designs, um mehr Prozessoren auf einem Stück Silizium unterzubringen.
Eine weitere Technik, die in letzter Zeit immer beliebter geworden ist, ist das Multithreading. Beim Multithreading, wenn der Prozessor Daten aus dem langsamen Systemspeicher holen muss, wechselt der Prozessor zu einem anderen Programm oder Programm-Thread, der zur Ausführung bereit ist, anstatt auf das Eintreffen der Daten zu warten. Obwohl dies ein bestimmtes Programm/einen bestimmten Thread nicht beschleunigt, erhöht es doch den gesamten Systemdurchsatz, indem es die Zeit reduziert, in der die CPU im Leerlauf ist.
Konzeptionell ist Multithreading gleichbedeutend mit einem Kontextwechsel auf Betriebssystemebene. Der Unterschied besteht darin, dass eine Multithreading-CPU einen Thread-Wechsel in einem CPU-Zyklus ausführen kann, anstatt der Hunderte oder Tausende von CPU-Zyklen, die ein Kontextwechsel normalerweise erfordert. Dies wird erreicht, indem die Zustands-Hardware (wie z.B. die Registerdatei und der Programmzähler) für jeden aktiven Thread repliziert wird.
Eine weitere Verbesserung ist das simultane Multithreading. Diese Technik ermöglicht es superskalaren CPUs, Befehle von verschiedenen Programmen/Threads gleichzeitig im selben Zyklus auszuführen.
Verwandte Seiten
- Mikroprozessor
- Mikrocontroller
- Mehrkernprozessor
- Digitaler Signalprozessor
- CPU-Entwurf
- Datenpfad
- Parallelität auf Anweisungsebene (ILP)
Fragen und Antworten
F: Was ist Mikroarchitektur?
A: Mikroarchitektur ist eine Beschreibung der elektrischen Schaltung eines Computers, einer Zentraleinheit oder eines digitalen Signalprozessors, die ausreicht, um die Funktionsweise der Hardware vollständig zu beschreiben.
F: Wie wird dieses Konzept von Wissenschaftlern bezeichnet?
A: Wissenschaftler verwenden den Begriff "Computerorganisation", wenn sie sich auf die Mikroarchitektur beziehen.
F: Wie spricht man in der Computerindustrie von diesem Konzept?
A: In der Computerbranche spricht man häufiger von "Mikroarchitektur", wenn es um dieses Konzept geht.
F: Aus welchen beiden Bereichen besteht die Computerarchitektur?
A: Mikroarchitektur und Befehlssatzarchitektur (ISA) bilden zusammen den Bereich der Computerarchitektur.
F: Wofür steht ISA?
A: ISA steht für Instruction Set Architecture (Befehlssatzarchitektur).
F: Wofür steht µArch? A: µArch steht für Microarchitecture.
Verwandte Artikel
Autor
AlegsaOnline.com Mikroarchitektur Leandro Alegsa
URL: https://de.alegsaonline.com/art/64586
Quellen
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture