ASCII – Definition und vollständige Zeichentabelle (Binärcode & Steuerzeichen)
ASCII verständlich erklärt: Definition, vollständige Zeichentabelle, Binärcode & Steuerzeichen – mit Binär-/Hex-Werten, Beispielen und Praxiswissen für Entwickler und IT-Interessierte.
ASCII (ausgesprochen „az-kee“, in amerikanischem Englisch oft „ass-key“) ist eine standardisierte Tabelle von Zeichen für Computer. Es handelt sich um einen Binärcode, mit dem elektronische Geräte Text mit dem englischen Alphabet, Ziffern und anderen gebräuchlichen Symbolen darstellen und verarbeiten. ASCII steht für American Standard Code for Information Interchange (Amerikanischer Standardcode für den Informationsaustausch). Der Code wurde in den 1960er-Jahren entwickelt und basiert auf früheren Codes, die in Telegrafen- und Fernschreibesystemen verwendet wurden.
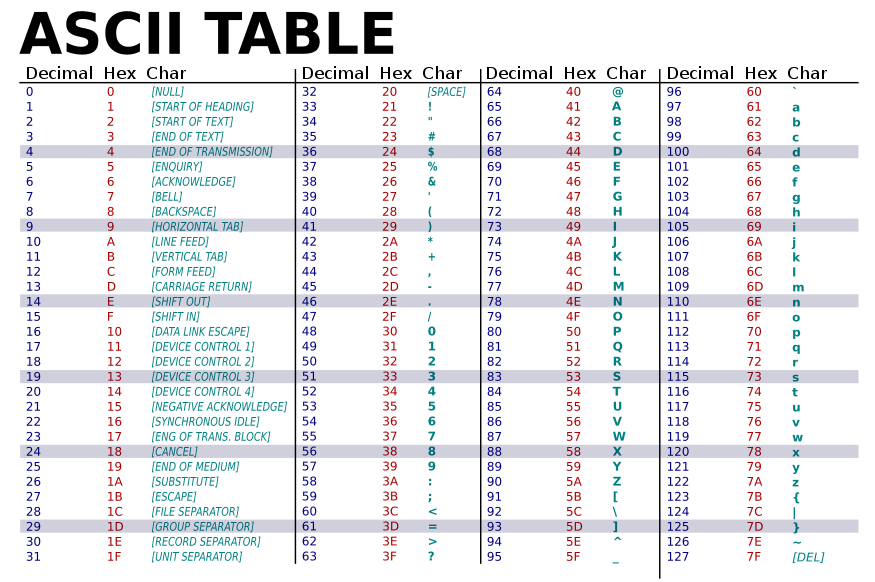
Wichtig zu korrigieren: ASCII ist ursprünglich ein 7-Bit-Code und definiert 128 Zeichen (Nummern 0–127). Die Aussage, ASCII verwende 8 Bits, ist irreführend: Die Norm selbst benennt 7 Bits pro Zeichen. In der Praxis wurden ASCII-Zeichen oft in 8-Bit-Bytes gespeichert oder über serielle Leitungen mit einem zusätzlichen Paritätsbit übertragen; dabei ergibt sich häufig eine 8-Bit-Darstellung wie 01000001 für den Großbuchstaben A. Im reinen 7-Bit-Format ist A als 1000001 (binär) kodiert, das entspricht 65 in Dezimal und 41 in hexadezimal. Acht Bits (ein Byte) ermöglichten historisch das Hinzufügen eines Paritätsbits zur einfachen Fehlererkennung bei verrauschten Verbindungen.
Bildergalerie
1 Bild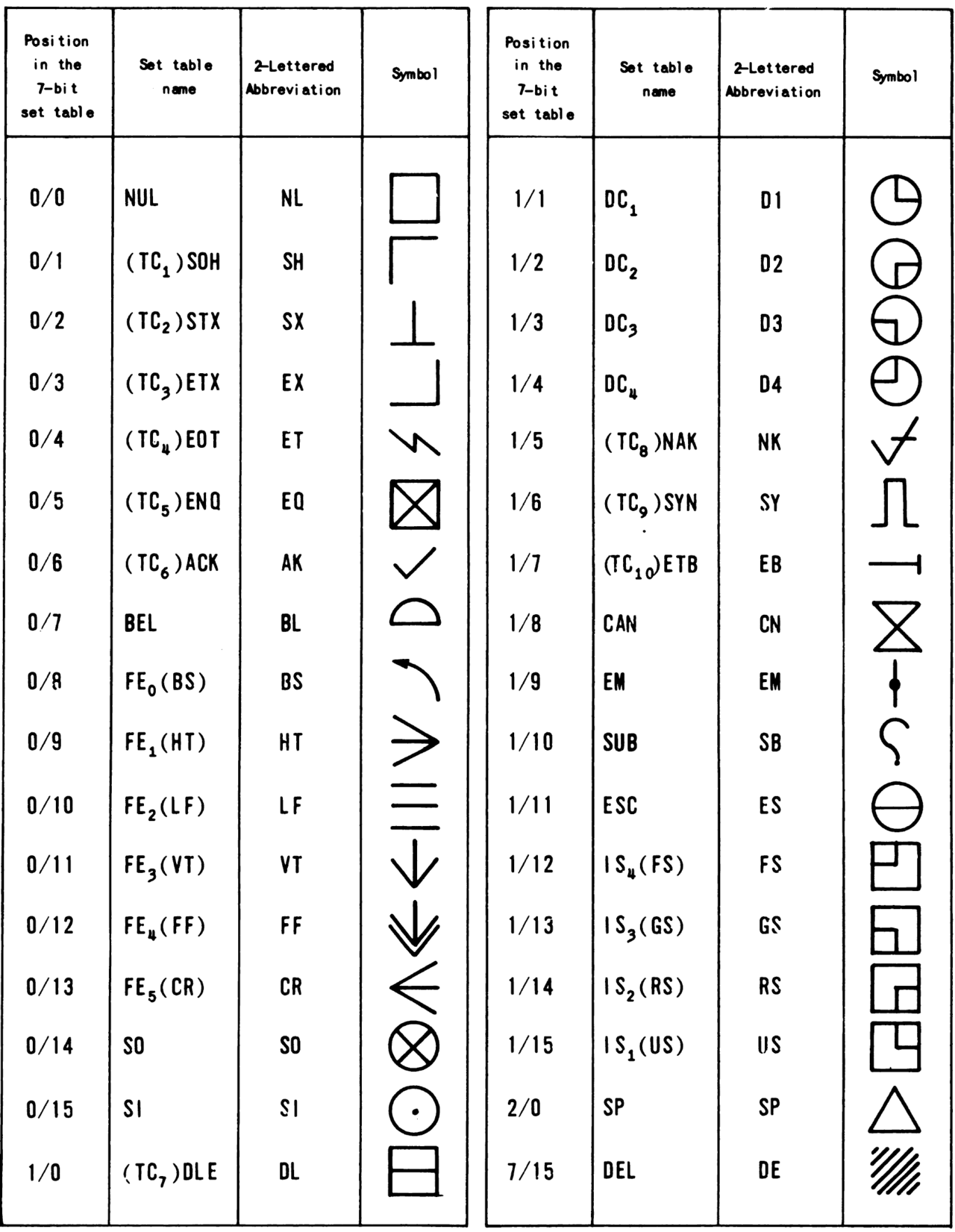
Zeichenbereiche und Beispiele
Die 128 ASCII-Codes gliedern sich grob in:
- Kontrollzeichen (0–31) und DEL (127): nicht druckbare Steuerzeichen wie NUL, BEL, BS, LF (Line Feed), CR (Carriage Return) etc.
- Druckbare Zeichen (32–126): Leerzeichen, Satzzeichen, Ziffern, Groß- und Kleinbuchstaben und weitere Symbole.
Wichtige Bereiche (dezimal):
- 0–31: Steuerzeichen (z. B. NUL=0, BEL=7, BS=8, TAB/HT=9, LF=10, CR=13)
- 32: Leerzeichen (Space)
- 48–57: Ziffern '0'–'9'
- 65–90: Großbuchstaben 'A'–'Z' (z. B. A = 65, hex 41)
- 97–122: Kleinbuchstaben 'a'–'z'
- 127: DEL (Delete) – historisch für das Entfernen von Zeichen auf Lochband/Lochstreifen verwendet
Steuerzeichen – Bedeutung und heutige Verwendung
Die Steuerzeichen wurden ursprünglich zur Steuerung von Druckern, Terminals und Übertragungsleitungen eingeführt. Beispiele und ihre heutige Relevanz:
- LF (Line Feed, 10): Wechselt in viele Systeme in die nächste Textzeile; in Unix/Linux als neues Zeilenende (\n) üblich.
- CR (Carriage Return, 13): Wagenrücklauf – in klassischen Druckern relevant; in Kombination CR+LF (13+10) als Zeilenende unter Windows genutzt.
- BEL (Bell, 7): Erzeugte früher ein akustisches Signal (Glocke) am Terminal.
- BS (Backspace, 8) und TAB (Horizontal Tab, 9): Steuern Position und Einrückung.
Viele Steuerzeichen werden heute nicht mehr für ihre ursprüngliche Hardwaresteuerung gebraucht, sind aber in Dateiformaten, Protokollen und bei der Textverarbeitung weiterhin relevant (z. B. zur Zeilenaufteilung oder als Steuerbytes in Binärprotokollen).
Historischer Hintergrund
ASCII entstand Anfang der 1960er-Jahre als einheitlicher Standard, um die Kommunikation zwischen verschiedenen Geräten, Herstellern und Systemen zu erleichtern. Die Norm wurde mehrmals überarbeitet (erste Version 1963, spätere Revisionen in den 1960er-/1970er-Jahren). Sie löste ältere Telegrafencodes ab und bildete die Basis für viele frühe Computerprotokolle und Dateiformate.
Erweiterungen und Nachfolger
Da ASCII nur die Grundzeichen des englischen Schriftsystems umfasst, entstanden ab den 1980er-Jahren zahlreiche 8-Bit-Erweiterungen (oft als „Extended ASCII“ bezeichnet), die weitere Zeichen für andere Sprachen und grafische Symbole enthielten — Beispiele sind ISO-8859-1 (Latein-1) und Windows-1252. Diese Erweiterungen verwendeten das achte Bit, um die Anzahl der verfügbaren Zeichen auf 256 zu erhöhen.
Mittlerweile ist Unicode (z. B. UTF-8) der dominierende Standard, weil er nahezu alle Schriftzeichen der Welt abbilden kann. Ein wichtiger Vorteil: UTF-8 ist abwärtskompatibel zu ASCII — Bytes mit Werten unter 128 entsprechen exakt den ASCII-Zeichen.
Praktische Hinweise
- Wenn jemand von einer „ASCII-Datei“ spricht, ist meist ein reiner Klartext (Plaintext) ohne spezielle Formatierungsinformationen gemeint.
- Beim Austausch von Textdateien zwischen Systemen muss man die unterschiedlichen Zeilenendungen beachten (Unix: LF, Windows: CR+LF, alte macOS-Versionen: CR).
- In Programmiersprachen und Netzwerkprotokollen werden ASCII-Codes häufig direkt verwendet (z. B. in HTTP-Headern oder beim Parsen von Text).
Zusammenfassung: ASCII ist ein einfacher, historisch bedeutsamer Zeichencode mit 128 definierten Zeichen (7 Bit). Er legte das Fundament für die Textverarbeitung in frühen Computern und bleibt durch seine Kompatibilität zu modernen Encodings wie UTF-8 weiterhin relevant.

Erweitertes ASCII
ASCII hat keine diakritischen Zeichen (Zeichen, die zu einem Buchstaben hinzugefügt werden, wie die Punkte (Umlaute) über Vokalen im Deutschen oder die Tilde (~) über dem "n" für das "ñ" im Spanischen). Es war nur für Englisch gedacht und funktioniert für die meisten anderen Sprachen nicht gut. Einige englische Wörter, die aus anderen Sprachen entlehnt sind, verwenden diese Markierungen ebenfalls, wie z.B. resumé (siehe Anhang: Englische Wörter mit diakritischen Zeichen).
Dies führte dazu, dass einige Systeme 8 Bit (ein volles Byte) anstelle von 7 Bit verwendeten. Der richtige Name für Systeme, die 8 Bit verwenden, heißt Extended ASCII. Acht Bits ermöglichen 256 Zeichen. Die ersten 128 Zeichen müssen die gleichen sein wie bei ASCII, und die restlichen werden normalerweise für alphabetische Buchstaben mit Akzenten verwendet, zum Beispiel wie É, È, Î und Ü. Damit ist das Problem für Sprachen gelöst, die auf dem lateinischen Alphabet basieren, obwohl nicht alle erweiterten ASCII-Systeme gleich sind. Andere Alphabete, wie das griechische Alphabet oder das kyrillische Alphabet, benötigen einen anderen Zeichensatz. Und einige Systeme wie diejenigen, die chinesische Zeichen verwenden, funktionieren immer noch nicht, da sie Tausende von Zeichen verwenden. Daher wurde Unicode geschaffen, um ein gemeinsames System für alle Sprachen zu haben.
Standard-ASCII wird immer noch häufig verwendet, insbesondere in Computersoftware und HTML-Dateien. Bis 2010 war es der Standard für URLs. Häufig wird eine Website, die Felder zur Eingabe von Text hat, nur ASCII-Text verwenden. Spezielle Markierungen für fettgedruckten oder zentrierten Text usw. werden fälschlicherweise angezeigt.
Fragen und Antworten
F: Was ist ASCII?
A: ASCII ist eine Zeichentabelle für Computer, die das englische Alphabet, Zahlen und andere gebräuchliche Symbole in einem Binärcode verarbeitet.
F: Was bedeutet ASCII?
A: ASCII steht für American Standard Code for Information Interchange.
F: Wann wurde ASCII entwickelt?
A: ASCII wurde in den 1960er Jahren entwickelt.
F: Wie viele Zeichen sind in dem Code enthalten?
A: Der Code enthält Definitionen für 128 Zeichen, denen Nummern von 0 bis 127 zugeordnet sind.
F: Wie viele Bits werden benötigt, um ein ASCII-Zeichen darzustellen?
A: Zur Darstellung eines ASCII-Zeichens sind 7 binäre Ziffern (Bits) erforderlich.
F: Verwendet eine ASCII-Computerdatei ein Byte pro Zeichen?
A: Ja, eine ASCII-Computerdatei verwendet ein Byte pro Zeichen, mit 8 Bits pro Byte.
F: Wird der ASCII-Standard heute noch häufig verwendet? A: Ja, der Standard-ASCII wird auch heute noch häufig verwendet, insbesondere in Computersoftware und HTML-Dateien.
Verwandte Artikel
Autor
AlegsaOnline.com ASCII – Definition und vollständige Zeichentabelle (Binärcode & Steuerzeichen) Leandro Alegsa
URL: https://de.alegsaonline.com/art/6475
Quellen
- robelle.com : "ASCII Character Set"
- asciitable.com : "ASCII table & description"