RAID
Inhalt · 1 Einleitung o 1.1 Unterschied zwischen physischen Datenträgern und logischen Datenträgern o 1.2 Lesen und Schreiben von Daten o 1.3 Was ist RAID? o 1.4 Warum RAID verwenden? o 1.5 Geschichte · 2 Von RAID-Systemen verwendete grundlegend…
Inhalt
· 1 Einleitung
o 1.1 Unterschied zwischen physischen Datenträgern und logischen Datenträgern
o 1.2 Lesen und Schreiben von Daten
o 1.3 Was ist RAID?
o 1.4 Warum RAID verwenden?
o 1.5 Geschichte
· 2 Von RAID-Systemen verwendete grundlegende Konzepte
o 2.1 Zwischenspeicherung
o 2.2 Spiegelung: Mehr als eine Kopie der Daten
o 2.3 Streifenbildung: Ein Teil der Daten befindet sich auf einer anderen Platte
o 2.4 Fehlerkorrektur und Fehler
o 2.5 Hot Spare: mehr Platten als benötigt verwenden
o 2.6 Streifen- und Brockengröße: Verteilung der Daten auf mehrere Platten
o 2.7 Zusammenbau der Festplatte: JBOD, Verkettung oder Überspannen
o 2.8 Klonen von Laufwerken
o 2.9 Verschiedene Aufstellungen
· 3 Grundlagen: einfache RAID-Level
o 3.1 Häufig verwendete RAID-Level
§ 3.1.1 RAID 0 "Streifenbildung".
§ 3.1.2 RAID 1 "Spiegelung"
§ 3.1.3 RAID 5 "Striping mit verteilter Parität"
§ 3.1.4 Bilder
o 3.2 Weniger genutzte RAID-Level
§ 3.2.1 RAID 2
§ 3.2.2 RAID 3 "Striping mit dedizierter Parität".
§ 3.2.3 RAID 4 "Striping mit dedizierter Parität"
§ 3.2.4 RAID 6
§ 3.2.5 Bilder
o 3.3 Nicht standardmäßige RAID-Level
§ 3.3.1 Doppelte Parität / Diagonale Parität
§ 3.3.2 RAID-DP
§ 3.3.3 RAID 1.5
§ 3.3.4 RAID 5E, RAID 5EE und RAID 6E
§ 3.3.5 RAID 7
§ 3.3.6 Intel-Matrix-RAID
§ 3.3.7 Linux MD RAID-Treiber
§ 3.3.8 RAID Z
§ 3.3.9 Bilder
· 4 Verbinden von RAID-Levels
· 5 Erstellen eines RAID
o 5.1 Software-RAID
o 5.2 Hardware-RAID
o 5.3 Hardware-unterstütztes RAID
· 6 Verschiedene Begriffe im Zusammenhang mit Hardware-Ausfällen
o 6.1 Misserfolgsrate
o 6.2 Mittlere Zeit bis zum Datenverlust
o 6.3 Mittlere Zeit bis zur Genesung
o 6.4 Nicht wiederherstellbare Bitfehlerrate
· 7 Probleme mit RAID
o 7.1 Hinzufügen von Datenträgern zu einem späteren Zeitpunkt
o 7.2 Verknüpfte Ausfälle
o 7.3 Atomarität
o 7.4 Nicht wiederherstellbare Daten
o 7.5 Schreib-Cache-Zuverlässigkeit
o 7.6 Kompatibilität der Ausrüstung
· 8 Was RAID kann und was nicht
o 8.1 Was RAID leisten kann
o 8.2 Was RAID nicht kann
· 9 Beispiel
· 10 Literaturhinweise
· 11 Andere Websites
RAID ist ein Akronym, das für Redundant Array of Inexpensive Disks (Redundant Array of Inexpensive Disks) oder Redundant Array of Independent Disks (Redundant Array of Independent Disks) steht. RAID ist ein Begriff aus der Computerbranche. Bei RAID werden mehrere Festplatten zu einer logischen Platte zusammengefasst. Es gibt verschiedene Möglichkeiten, dies zu erreichen. Jede der Methoden, bei der die Festplatten zusammengesetzt werden, hat einige Vor- und Nachteile gegenüber der Verwendung der Laufwerke als einzelne, voneinander unabhängige Platten. Die Hauptgründe, warum RAID verwendet wird, sind
- Damit der Datenverlust seltener auftritt. Dies wird durch mehrere Kopien der Daten erreicht.
- Mehr Speicherplatz durch viele kleinere Festplatten zu erhalten.
- Um mehr Flexibilität zu erhalten (Platten können geändert oder hinzugefügt werden, während das System weiterläuft)
- Um die Daten schneller zu erhalten.
Es ist nicht möglich, alle diese Ziele gleichzeitig zu erreichen, so dass Entscheidungen getroffen werden müssen.
Es gibt auch einige schlechte Dinge:
- Bestimmte Auswahlmöglichkeiten können davor schützen, dass Daten verloren gehen, weil eine (oder mehrere) Platten ausgefallen sind. Sie schützen jedoch nicht davor, dass die Daten gelöscht oder überschrieben werden.
- In einigen Konfigurationen kann RAID tolerieren, dass eine oder mehrere Festplatten ausfallen. Nachdem die ausgefallenen Platten ersetzt worden sind, müssen die Daten rekonstruiert werden. Je nach Konfiguration und Größe der Platten kann diese Rekonstruktion viel Zeit in Anspruch nehmen.
- Bestimmte Arten von Fehlern machen es unmöglich, die Daten zu lesen
Die meisten Arbeiten zum RAID basieren auf einer Arbeit aus dem Jahr 1988.
Seit der Entwicklung dieser Technologie haben Unternehmen RAID-Systeme zur Speicherung ihrer Daten verwendet. Es gibt verschiedene Möglichkeiten, RAID-Systeme herzustellen. Seit seiner Entdeckung sind die Kosten für den Aufbau eines RAID-Systems stark gesunken. Aus diesem Grund verfügen sogar einige Computer und Geräte, die zu Hause verwendet werden, über einige RAID-Funktionen. Solche Systeme können zum Beispiel zum Speichern von Musik oder Filmen verwendet werden.
Einführung
Unterschied zwischen physischen Platten und logischen Platten
Eine Festplatte ist ein Teil eines Computers. Normale Festplatten verwenden Magnetismus, um Informationen zu speichern. Wenn Festplatten verwendet werden, stehen sie dem Betriebssystem zur Verfügung. In Microsoft Windows erhält jede Festplatte einen Laufwerksbuchstaben (beginnend mit C:, A: oder B: sind für Diskettenlaufwerke reserviert). Unix- und Linux-ähnliche Betriebssysteme haben einen einwurzligen Verzeichnisbaum. Das bedeutet, dass die Benutzer der Computer manchmal nicht wissen, wo die Informationen gespeichert sind (fairerweise wissen viele Windows-Benutzer auch nicht, wo ihre Daten gespeichert sind).
In der Informatik werden die Festplatten (bei denen es sich um Hardware handelt und die angefasst werden können) manchmal als physische Laufwerke oder physische Platten bezeichnet. Was das Betriebssystem dem Benutzer anzeigt, wird manchmal als logische Platte bezeichnet. Ein physisches Laufwerk kann in verschiedene Abschnitte unterteilt werden, die als Plattenpartitionen bezeichnet werden. Normalerweise enthält jede Plattenpartition ein Dateisystem. Das Betriebssystem zeigt jede Partition wie eine logische Festplatte an.
Daher werden für den Benutzer sowohl die Einrichtung mit vielen physischen Platten als auch die Einrichtung mit vielen logischen Platten gleich aussehen. Der Benutzer kann nicht entscheiden, ob ein "logischer Datenträger" mit einem physischen Datenträger identisch ist oder ob er einfach ein Teil des Datenträgers ist. Storage Area Networks (SANs) ändern diese Ansicht vollständig. Alles, was von einem SAN sichtbar ist, ist eine Anzahl von logischen Platten.
Lesen und Schreiben von Daten
Im Computer werden Daten in Form von Bits und Bytes organisiert. In den meisten Systemen bilden 8 Bits ein Byte. Der Computerspeicher verwendet Elektrizität, um die Daten zu speichern, Festplatten verwenden Magnetismus. Wenn also Daten auf eine Platte geschrieben werden, wird das elektrische Signal in ein magnetisches Signal umgewandelt. Wenn Daten von der Platte gelesen werden, erfolgt die Umwandlung in die andere Richtung: Aus der Polarität eines Magnetfeldes wird ein elektrisches Signal erzeugt.
Was ist RAID?
Ein RAID-Array verbindet zwei oder mehr Festplatten so, dass sie eine logische Festplatte bilden. Es gibt verschiedene Gründe, warum dies getan wird. Die häufigsten sind:
- Stoppen des Datenverlusts, wenn eine oder mehrere Platten des Arrays ausfallen.
- Schnellerer Datentransfer.
- Sie erhalten die Möglichkeit, die Festplatten zu wechseln, während das System weiter läuft.
- Zusammenfügen mehrerer Platten, um mehr Speicherkapazität zu erhalten; manchmal werden viele billige Platten verwendet, statt einer teureren.
RAID wird durch den Einsatz spezieller Hardware oder Software auf dem Computer realisiert. Die verbundenen Festplatten sehen dann für den Benutzer wie eine einzige Festplatte aus. Die meisten RAID-Level erhöhen die Redundanz. Das bedeutet, dass sie die Daten öfter speichern, oder sie speichern Informationen darüber, wie die Daten zu rekonstruieren sind. Dadurch kann eine Reihe von Platten ausfallen, ohne dass die Daten verloren gehen. Wenn die ausgefallene Platte ersetzt wird, werden die Daten, die sie enthalten sollte, von den anderen Platten des Systems kopiert oder wiederhergestellt. Dies kann sehr lange dauern. Wie lange es dauert, hängt von verschiedenen Faktoren ab, wie z.B. der Größe des Arrays.
Warum RAID verwenden?
Einer der Gründe, warum viele Unternehmen RAID verwenden, ist, dass die Daten im Array einfach verwendet werden können. Diejenigen, die die Daten verwenden, müssen sich nicht bewusst sein, dass sie überhaupt RAID verwenden. Wenn ein Fehler aufgetreten ist und das Array sich erholt, wird der Zugriff auf die Daten langsamer sein. Der Zugriff auf die Daten während dieser Zeit verlangsamt auch den Wiederherstellungsprozess, aber das ist immer noch viel schneller, als gar nicht mit den Daten arbeiten zu können. Abhängig vom RAID-Level kann es jedoch sein, dass Platten nicht ausfallen, während die neue Platte für die Verwendung vorbereitet wird. Der Ausfall einer Platte zu diesem Zeitpunkt hat den Verlust aller Daten im Array zur Folge.
Die verschiedenen Möglichkeiten, Festplatten zu verbinden, werden als RAID-Level bezeichnet. Eine größere Anzahl für den Level ist nicht unbedingt besser. Verschiedene RAID-Level haben unterschiedliche Zwecke. Einige RAID-Level benötigen spezielle Festplatten und spezielle Controller.
Geschichte
1978 machte ein Mann namens Norman Ken Ouchi, der bei IBM arbeitete, einen Vorschlag, in dem er die Pläne für das spätere RAID 5 beschrieb. Die Pläne beschrieben auch etwas Ähnliches wie RAID 1 sowie den Schutz eines Teils von RAID 4.
Mitarbeiter der Universität von Berkeley halfen 1987 bei der Planung der Forschung. Sie versuchten, es der RAID-Technologie zu ermöglichen, zwei statt einer Festplatte zu erkennen. Sie stellten fest, dass die RAID-Technologie mit zwei Festplatten einen viel besseren Speicherplatz bot als mit nur einer Festplatte. Es stürzte jedoch viel öfter ab.
Im Jahr 1988 wurden die verschiedenen RAID-Typen (1 bis 5) von David Patterson, Garth Gibson und Randy Katz in ihrem Artikel mit dem Titel "Ein Fall für redundante Anordnungen kostengünstiger Festplatten (RAID)" beschrieben. Dieser Artikel war der erste, der die neue Technologie RAID nannte, und der Name wurde offiziell.


Von RAID-Systemen verwendete grundlegende Konzepte
RAID verwendet einige grundlegende Ideen, die in dem 1994 veröffentlichten Artikel "RAID: High-Performance, Reliable Secondary Storage" von Peter Chen und anderen beschrieben wurden.
Caching
Caching ist eine Technologie, die auch in RAID-Systemen Anwendung findet. Es gibt verschiedene Arten von Caches, die in RAID-Systemen verwendet werden:
- Betriebssystem
- RAID-Controller
- Festplatten-Array für Unternehmen
In modernen Systemen wird eine Schreibanforderung als erledigt angezeigt, wenn die Daten in den Cache geschrieben wurden. Dies bedeutet nicht, dass die Daten auf die Platte geschrieben worden sind. Anforderungen aus dem Cache werden nicht unbedingt in der gleichen Reihenfolge behandelt, in der sie in den Cache geschrieben wurden. Dadurch ist es möglich, dass bei einem Systemausfall manchmal einige Daten nicht auf die betroffene Platte geschrieben wurden. Aus diesem Grund verfügen viele Systeme über einen Cache, der durch eine Batterie gesichert wird.
Spiegelung: Mehr als eine Kopie der Daten
Wenn von einem Spiegel die Rede ist, ist dies eine sehr einfache Idee. Anstatt die Daten nur an einem Ort zu speichern, gibt es mehrere Kopien der Daten. Diese Kopien befinden sich normalerweise auf verschiedenen Festplatten (oder Plattenpartitionen). Wenn es zwei Kopien gibt, kann eine davon ausfallen, ohne dass die Daten betroffen sind (da sie sich immer noch auf der anderen Kopie befinden). Die Spiegelung kann auch beim Lesen von Daten einen Schub geben. Es wird immer von der schnellsten Platte genommen, die antwortet. Das Schreiben von Daten ist jedoch langsamer, da alle Platten aktualisiert werden müssen.
Ausziehen: Ein Teil der Daten befindet sich auf einer anderen Platte
Beim Striping werden die Daten in verschiedene Teile aufgeteilt. Diese Teile landen dann auf verschiedenen Platten (oder Plattenpartitionen). Das bedeutet, dass das Schreiben von Daten schneller ist, da es parallel durchgeführt werden kann. Dies bedeutet jedoch nicht, dass es keine Fehler gibt, da jeder Datenblock nur auf einer Platte gefunden wird.
Fehlerkorrektur und Fehler
Es ist möglich, verschiedene Arten von Prüfsummen zu berechnen. Einige Methoden zur Berechnung von Prüfsummen erlauben es, einen Fehler zu finden. Die meisten RAID-Level, die Redundanz verwenden, können dies tun. Einige Methoden sind schwieriger zu handhaben, aber sie erlauben es, den Fehler nicht nur zu erkennen, sondern auch zu beheben.
Hot Spare: mehr Platten als benötigt
Viele der Möglichkeiten, wie RAID etwas unterstützen kann, werden als Hot Spare bezeichnet. Ein Hot-Spare ist eine leere Platte, die im normalen Betrieb nicht verwendet wird. Wenn eine Platte ausfällt, können Daten direkt auf die Hot-Spare-Platte kopiert werden. Auf diese Weise muss die ausgefallene Platte durch eine neue leere Platte ersetzt werden, um zum Hot-Spare zu werden.
Streifen- und Brockengröße: Verteilung der Daten auf mehrere Platten
RAID funktioniert, indem die Daten auf mehrere Platten verteilt werden. Zwei der in diesem Zusammenhang häufig verwendeten Begriffe sind Strip-Größe und Chunk-Größe.
Die Chunk-Größe ist der kleinste Datenblock, der auf eine einzelne Platte des Arrays geschrieben wird. Die Stripe-Größe ist die Größe eines Datenblocks, der über alle Platten verteilt wird. Auf diese Weise werden bei vier Platten und einer Stripe-Größe von 64 Kilobyte (kB) 16 kB auf jede Platte geschrieben. Die Chunk-Größe in diesem Beispiel beträgt also 16 kB. Eine größere Stripe-Größe bedeutet eine schnellere Datenübertragungsrate, aber auch eine größere maximale Latenzzeit. In diesem Fall ist dies die Zeit, die benötigt wird, um einen Datenblock zu erhalten.
Diskette zusammensetzen: JBOD, Verkettung oder Überbrückung
Viele Controller (und auch Software) können Platten auf folgende Weise zusammensetzen: Sie nehmen die erste Platte, bis sie endet, dann nehmen sie die zweite, und so weiter. Auf diese Weise sehen mehrere kleinere Platten wie eine größere aus. Dies ist nicht wirklich RAID, da es keine Redundanz gibt. Außerdem können durch Spanning Platten kombiniert werden, bei denen RAID 0 nichts ausrichten kann. Im Allgemeinen wird dies nur als ein Bündel von Platten (JBOD) bezeichnet.
Dies ist wie ein entfernter Verwandter von RAID, da das logische Laufwerk aus verschiedenen physischen Laufwerken besteht. Verkettung wird manchmal verwendet, um mehrere kleine Laufwerke in ein größeres nutzbares Laufwerk zu verwandeln. Dies ist bei RAID 0 nicht möglich. JBOD könnte zum Beispiel 3 GB-, 15 GB-, 5,5 GB- und 12 GB-Laufwerke zu einem logischen Laufwerk mit 35,5 GB kombinieren, was oft nützlicher ist als die Laufwerke allein.
In dem Diagramm rechts sind die Daten vom Ende von Platte 0 (Block A63) mit dem Anfang von Platte 1 (Block A64); Ende von Platte 1 (Block A91) mit dem Anfang von Platte 2 (Block A92) verkettet. Wenn RAID 0 verwendet würde, würden Platte 0 und Platte 2 auf 28 Blöcke verkürzt werden, was der Größe der kleinsten Platte im Array (Platte 1) bei einer Gesamtgröße von 84 Blöcken entspricht.
Einige RAID-Controller verwenden JBOD, um über die Arbeit auf Laufwerken ohne RAID-Funktionen zu sprechen. Jedes Laufwerk wird im Betriebssystem separat angezeigt. Dieses JBOD ist nicht dasselbe wie Verkettung.
Viele Linux-Systeme verwenden die Begriffe "linearer Modus" oder "Append-Modus". Die Mac OS X 10.4-Implementierung - als "Concatenated Disk Set" bezeichnet - hinterlässt dem Benutzer keine brauchbaren Daten auf den verbleibenden Laufwerken, wenn ein Laufwerk in einem "Concatenated Disk Set" ausfällt, obwohl die Platten ansonsten wie oben beschrieben funktionieren.
Verkettung ist eine der Anwendungen des Logical Volume Manager unter Linux. Sie kann verwendet werden, um virtuelle Laufwerke zu erstellen.
Laufwerk-Klon
Die meisten modernen Festplatten verfügen über einen Standard namens Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T.). SMART ermöglicht es, bestimmte Dinge auf einer Festplatte zu überwachen. Bestimmte Controller erlauben es, eine einzelne Festplatte zu ersetzen, noch bevor sie ausfällt, z.B. weil S.M.A.R.T oder ein anderer Disk-Test zu viele korrigierbare Fehler meldet. Zu diesem Zweck kopiert der Controller alle Daten auf ein Hot-Spare-Laufwerk. Danach kann die Platte durch eine andere ersetzt werden (die dann einfach das neue Hot-Spare-Laufwerk wird).
Verschiedene Aufstellungen
Die Einrichtung der Platten und die Art und Weise, wie sie die oben genannten Techniken verwenden, beeinflussen die Leistung und Zuverlässigkeit des Systems. Wenn mehrere Platten verwendet werden, ist es wahrscheinlicher, dass eine der Platten ausfällt. Aus diesem Grund müssen Mechanismen gebaut werden, die in der Lage sind, Fehler zu finden und zu beheben. Dadurch wird das gesamte System zuverlässiger, da es in der Lage ist, den Ausfall zu überleben und zu beheben.

Grundlagen: einfache RAID-Level
Häufig verwendete RAID-Level
RAID 0 "Streifenbildung
RAID 0 ist nicht wirklich ein RAID, da es nicht redundant ist. Bei RAID 0 werden die Platten einfach zu einer großen Platte zusammengesetzt. Dies wird als "Striping" bezeichnet. Wenn eine Platte ausfällt, fällt das gesamte Array aus. Daher wird RAID 0 selten für wichtige Daten verwendet, aber das Lesen und Schreiben von Daten von der Platte kann beim Striping schneller sein, da jede Platte einen Teil der Datei gleichzeitig liest.
Bei RAID 0 werden Plattenblöcke, die hintereinander kommen, in der Regel auf verschiedenen Platten platziert. Aus diesem Grund sollten alle von einem RAID 0 verwendeten Platten die gleiche Größe haben.
RAID 0 wird häufig für Swapspace unter Linux oder Unix-ähnlichen Betriebssystemen verwendet.
RAID 1 "Spiegelung
Bei RAID 1 werden zwei Festplatten zusammengesetzt. Beide enthalten die gleichen Daten, die eine "spiegelt" die andere. Dies ist eine einfache und schnelle Konfiguration, unabhängig davon, ob sie mit einem Hardware-Controller oder per Software implementiert wird.
RAID 5 "Striping mit verteilter Parität"
RAID-Level 5 wird wahrscheinlich die meiste Zeit verwendet. Zum Aufbau eines RAID 5-Speicherarrays werden mindestens drei Festplatten benötigt. Jeder Datenblock wird an drei verschiedenen Orten gespeichert. An zwei dieser Stellen wird der Block so gespeichert, wie er ist, auf der dritten wird eine Prüfsumme gespeichert. Diese Prüfsumme ist ein Spezialfall eines Reed-Solomon-Codes, der nur die bitweise Addition verwendet. Normalerweise wird sie mit der XOR-Methode berechnet. Da diese Methode symmetrisch ist, kann ein verlorener Datenblock aus dem anderen Datenblock und der Prüfsumme wieder aufgebaut werden. Für jeden Block wird eine andere Platte den Paritätsblock enthalten, der die Prüfsumme enthält. Dies geschieht, um die Redundanz zu erhöhen. Jede Platte kann ausfallen. Insgesamt gibt es eine Platte mit den Prüfsummen, so dass die gesamte nutzbare Kapazität diejenige aller Platten bis auf eine ist. Die Größe der resultierenden logischen Platte entspricht der Größe aller Platten zusammen, mit Ausnahme einer Platte, die die Paritätsinformationen enthält.
Dies ist natürlich langsamer als RAID-Level 1, da bei jedem Schreibvorgang alle Platten gelesen werden müssen, um die Paritätsinformationen zu berechnen und zu aktualisieren. Die Leseleistung von RAID 5 ist fast so gut wie die von RAID 0 für die gleiche Anzahl von Platten. Mit Ausnahme der Paritätsblöcke folgt die Verteilung der Daten auf die Laufwerke dem gleichen Muster wie bei RAID 0. Der Grund, warum RAID 5 etwas langsamer ist, liegt darin, dass die Platten die Paritätsblöcke überspringen müssen.
Ein RAID 5 mit einer ausgefallenen Festplatte funktioniert weiterhin. Es befindet sich im degradierten Modus. Ein degradiertes RAID 5 kann sehr langsam sein. Aus diesem Grund wird oft eine zusätzliche Platte hinzugefügt. Dies wird als Hot-Spare-Festplatte bezeichnet. Wenn eine Platte ausfällt, können die Daten direkt auf der zusätzlichen Platte wiederhergestellt werden. RAID 5 kann auch recht einfach in Software ausgeführt werden.
Hauptsächlich aufgrund von Leistungsproblemen bei ausgefallenen RAID 5-Arrays haben einige Datenbankexperten eine Gruppe namens BAARF-the Battle Against Any Raid Five gebildet.
Wenn das System ausfällt, während aktiv geschrieben wird, kann die Parität eines Streifens mit den Daten inkonsistent werden. Wenn dies nicht repariert wird, bevor eine Platte oder ein Block ausfällt, kann es zu Datenverlust kommen. Eine falsche Parität wird verwendet, um den fehlenden Block in diesem Stripe zu rekonstruieren. Dieses Problem wird manchmal als "Schreibloch" bezeichnet. Batteriegesicherte Caches und ähnliche Techniken werden häufig verwendet, um die Wahrscheinlichkeit dieses Auftretens zu verringern.
Bilder
· 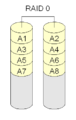
RAID 0 legt einfach die verschiedenen Blöcke auf die verschiedenen Platten. Es gibt keine Redundanz.
· 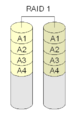
Bei Raid 1 ist jeder Block auf beiden Platten vorhanden
· 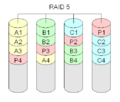
RAID 5 berechnet spezielle Prüfsummen für die Daten. Sowohl die Blöcke mit der Prüfsumme als auch die mit den Daten werden über alle Platten verteilt.
Weniger verwendete RAID-Level
RAID 2
Dies wurde bei sehr großen Computern verwendet. Für die Verwendung von RAID Level 2 sind spezielle teure Festplatten und ein spezieller Controller erforderlich. Die Daten werden auf Bit-Ebene verteilt (alle anderen Ebenen verwenden Aktionen auf Byte-Ebene). Es werden spezielle Berechnungen durchgeführt. Die Daten werden in statische Bit-Folgen aufgeteilt. 8 Datenbits und 2 Paritätsbits werden zusammengesetzt. Dann wird ein Hamming-Code berechnet. Die Fragmente des Hamming-Codes werden dann auf die verschiedenen Platten verteilt.
RAID 2 ist der einzige RAID-Level, der Fehler reparieren kann, die anderen RAID-Level können diese nur erkennen. Wenn sie feststellen, dass die benötigten Informationen keinen Sinn ergeben, werden sie sie einfach neu aufbauen. Dies geschieht durch Berechnungen unter Verwendung der Informationen auf den anderen Platten. Wenn diese Informationen fehlen oder falsch sind, können sie nicht viel tun. Da es Hamming-Codes verwendet, kann RAID 2 herausfinden, welche Information falsch ist, und nur diese Information korrigieren.
RAID 2 benötigt mindestens 10 Festplatten, um zu funktionieren. Aufgrund seiner Komplexität und des Bedarfs an sehr teurer und spezieller Hardware wird RAID 2 nicht mehr sehr häufig verwendet.
RAID 3 "Striping mit dedizierter Parität"
Raid-Level 3 ist dem RAID-Level 0 sehr ähnlich. Eine zusätzliche Platte wird hinzugefügt, um Paritätsinformationen zu speichern. Dies geschieht durch bitweise Addition des Wertes eines Blocks auf den anderen Platten. Die Paritätsinformationen werden auf einer separaten (dedizierten) Platte gespeichert. Das ist nicht gut, denn wenn die Paritätsplatte abstürzt, gehen die Paritätsinformationen verloren.
RAID Level 3 wird normalerweise mit mindestens 3 Festplatten durchgeführt. Ein Zwei-Platten-Setup ist identisch mit einem RAID-Level 0.
RAID 4 "Striping mit dedizierter Parität"
Dies ist dem RAID 3 sehr ähnlich, außer dass die Paritätsinformationen über größere Blöcke und nicht über einzelne Bytes berechnet werden. Dies ist wie RAID 5. Für ein RAID 4-Array werden mindestens drei Platten benötigt.
RAID 6
RAID-Level 6 war kein ursprünglicher RAID-Level. Er fügt einem RAID 5-Array einen zusätzlichen Paritätsblock hinzu. Es benötigt mindestens vier Platten (zwei Platten für die Kapazität, zwei Platten für die Redundanz). RAID 5 kann als Spezialfall eines Reed-Solomon-Codes angesehen werden. RAID 5 ist jedoch ein Sonderfall, es muss nur im Galois-Feld GF(2) hinzugefügt werden. Dies ist mit XORs leicht zu bewerkstelligen. RAID 6 erweitert diese Berechnungen. Es ist kein Sonderfall mehr, und alle Berechnungen müssen durchgeführt werden. Bei RAID 6 wird eine zusätzliche Prüfsumme (Polynom genannt) verwendet, in der Regel von GF (28). Mit diesem Ansatz ist es möglich, sich gegen eine beliebige Anzahl von ausgefallenen Platten zu schützen. RAID 6 ist für den Fall vorgesehen, dass zwei Prüfsummen zum Schutz vor dem Ausfall von zwei Platten verwendet werden.
Wie bei RAID 5 befinden sich Parität und Daten für jeden Block auf unterschiedlichen Platten. Die beiden Paritätsblöcke befinden sich ebenfalls auf unterschiedlichen Platten.
Es gibt verschiedene Möglichkeiten, RAID 6 auszuführen. Sie unterscheiden sich in ihrer Schreibleistung und in der Anzahl der erforderlichen Berechnungen. Schneller schreiben zu können, bedeutet in der Regel, dass mehr Berechnungen erforderlich sind.
RAID 6 ist langsamer als RAID 5, aber es ermöglicht die Fortsetzung des RAIDs mit zwei ausgefallenen Festplatten. RAID 6 wird immer beliebter, weil es ermöglicht, ein Array nach einem Ausfall einer einzelnen Festplatte wieder aufzubauen, selbst wenn eine der verbleibenden Festplatten einen oder mehrere defekte Sektoren aufweist.
Bilder
· 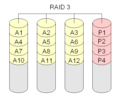
RAID 3 ist dem RAID-Level 0 sehr ähnlich. Es wird eine zusätzliche Platte hinzugefügt, die eine Prüfsumme für jeden Datenblock enthält.
· 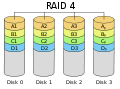
RAID 4 ist ähnlich wie RAID-Level 3, berechnet jedoch die Parität über größere Datenblöcke
· 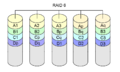
RAID 6 ist ähnlich wie RAID 5, berechnet jedoch zwei verschiedene Prüfsummen. Dies ermöglicht den Ausfall von zwei Platten ohne Datenverlust.
Nicht standardmäßige RAID-Level
Doppelte Parität / Diagonale Parität
RAID 6 verwendet zwei Paritätsblöcke. Diese werden auf besondere Weise über ein Polynom berechnet. RAID mit doppelter Parität (auch als RAID mit diagonaler Parität bezeichnet) verwendet für jeden dieser Paritätsblöcke ein anderes Polynom. Kürzlich sagte der Industrieverband, der RAID definiert hat, dass RAID mit doppelter Parität eine andere Form von RAID 6 ist.
RAID-DP
RAID-DP ist eine weitere Möglichkeit, doppelte Parität zu erreichen.
RAID 1.5
RAID 1.5 (nicht zu verwechseln mit RAID 15, das anders ist) ist eine proprietäre RAID-Implementierung. Wie RAID 1 verwendet es nur zwei Platten, aber es führt sowohl Striping als auch Spiegelung durch (ähnlich wie RAID 10). Die meisten Dinge werden in Hardware erledigt.
RAID 5E, RAID 5EE und RAID 6E
RAID 5E, RAID 5EE und RAID 6E (mit dem zusätzlichen E für Enhanced) beziehen sich im Allgemeinen auf verschiedene Typen von RAID 5 oder RAID 6 mit einem Hot-Spare. Bei diesen Implementierungen ist das Hot-Spare-Laufwerk kein physisches Laufwerk. Vielmehr existiert es in Form von freiem Speicherplatz auf den Platten. Dies erhöht die Leistung, aber es bedeutet, dass ein Hot-Spare-Laufwerk nicht von verschiedenen Arrays gemeinsam genutzt werden kann. Das System wurde um 2001 von IBM ServeRAID eingeführt.
RAID 7
Dies ist eine proprietäre Implementierung. Sie fügt einem RAID 3- oder RAID 4-Array Caching hinzu.
Intel-Matrix-RAID
Einige Intel-Hauptplatinen verfügen über einen RAID-Chip, der über diese Funktion verfügt. Er verwendet zwei oder drei Festplatten und partitioniert sie dann gleichmäßig, um eine Kombination aus RAID 0, RAID 1, RAID 5 oder RAID 1+0-Levels zu bilden.
Linux MD RAID-Treiber
Dies ist der Name für den Treiber, der es ermöglicht, Software-RAID unter Linux durchzuführen. Zusätzlich zu den normalen RAID-Levels 0-6 hat er auch eine RAID-10-Implementierung. Seit Kernel 2.6.9 ist RAID 10 eine einzige Ebene. Die Implementierung hat einige Nicht-Standard-Funktionen.
RAID Z
Sun hat ein Dateisystem namens ZFS implementiert. Dieses Dateisystem ist für die Verarbeitung großer Datenmengen optimiert. Es umfasst einen Logical Volume Manager. Es enthält auch eine Funktion namens RAID-Z. Es vermeidet das als RAID 5-Schreibloch bezeichnete Problem, da es über eine Copy-on-Write-Richtlinie verfügt: Es überschreibt die Daten nicht direkt, sondern schreibt neue Daten an einen neuen Ort auf der Platte. Wenn der Schreibvorgang erfolgreich war, werden die alten Daten gelöscht. Es vermeidet die Notwendigkeit von Lese-Änderungs-Schreib-Operationen bei kleinen Schreibvorgängen, da es nur Vollstreifen schreibt. Kleine Blöcke werden gespiegelt statt paritätsgeschützt, was möglich ist, weil das Dateisystem weiß, wie die Speicherung organisiert ist. Es kann daher bei Bedarf zusätzlichen Speicherplatz zuweisen. Es gibt auch RAID-Z2, das zwei Formen der Parität verwendet, um ähnliche Ergebnisse wie RAID 6 zu erzielen: die Fähigkeit, bis zu zwei Laufwerksausfälle ohne Datenverlust zu überstehen.
Bilder
· 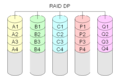
Diagramm eines RAID DP (Double Parity)-Aufbaus.
· 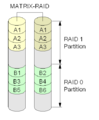
Eine Matrix-RAID-Einrichtung.
Verbinden von RAID-Levels
Mit RAID können verschiedene Platten zu einer logischen Platte zusammengesetzt werden, so dass der Benutzer nur die logische Platte sieht. Jeder der oben erwähnten RAID-Level hat gute und schlechte Punkte. Aber RAID kann auch mit logischen Platten arbeiten. Auf diese Weise kann einer der oben genannten RAID-Level mit einem Satz von logischen Platten verwendet werden. Viele Leute merken sich das, indem sie die Nummern zusammenschreiben. Manchmal schreiben sie ein '+' oder ein '&' dazwischen. Häufige Kombinationen (unter Verwendung von zwei Ebenen) sind die folgenden:
- RAID 0+1: Zwei oder mehr RAID 0-Arrays werden zu einem RAID 1-Array kombiniert; dies wird als Spiegel von Streifen bezeichnet
- RAID 1+0: Wie RAID 0+1, aber RAID-Level umgekehrt; Streifen aus Spiegeln. Dadurch werden Plattenausfälle seltener als bei RAID 0+1 oben.
- RAID 5+0: Streifen Sie mehrere RAID 5's mit einem RAID 0. Eine Platte jedes RAID 5 kann ausfallen, macht dieses RAID 5 jedoch zum Single-Point-of-Failure; wenn eine andere Platte dieses Arrays ausfällt, gehen alle Daten des Arrays verloren.
- RAID 5+1: Spiegeln eines Satzes von RAID 5: In Situationen, in denen das RAID aus sechs Platten besteht, können drei beliebige Platten ausfallen (ohne dass Daten verloren gehen).
- RAID 6+0: Strippen Sie mehrere RAID 6-Arrays über ein RAID 0; zwei Platten jedes RAID 6 können ohne Datenverlust ausfallen.
Mit sechs Platten zu je 300 GB, einer Gesamtkapazität von 1,8 TB, ist es möglich, ein RAID 5 mit 1,5 TB nutzbarem Speicherplatz einzurichten. In diesem Array kann eine Platte ohne Datenverlust ausfallen. Bei RAID 50 wird der Speicherplatz auf 1,2 TB reduziert, aber von jedem RAID 5 kann eine Platte ausfallen, was zu einer spürbaren Leistungssteigerung führt. Bei RAID 51 wird die nutzbare Größe auf 900 GB reduziert, es können jedoch drei beliebige Laufwerke ausfallen.
· 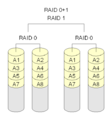
RAID 0+1: Mehrere RAID 0-Arrays werden mit einem RAID 1 kombiniert
· 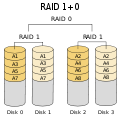
RAID 1+0: robuster als RAID 0+1; unterstützt mehrere Laufwerksausfälle, solange keine zwei Laufwerke einen Spiegelausfall verursachen.
· 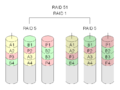
RAID 5+1: Davon können drei beliebige Laufwerke ausfallen, ohne Datenverlust.
Erstellen eines RAID
Es gibt verschiedene Möglichkeiten, ein RAID zu erstellen. Es kann entweder mit Software oder mit Hardware durchgeführt werden.
Software-RAID
Ein RAID kann mit Software auf zwei verschiedene Arten erstellt werden. Im Falle von Software-RAID werden die Platten wie normale Festplatten angeschlossen. Es ist der Computer, der das RAID zum Funktionieren bringt. Das bedeutet, dass die CPU bei jedem Zugriff auch die Berechnungen für das RAID durchführen muss. Die Berechnungen für RAID 0 oder RAID 1 sind einfach. Die Berechnungen für RAID 5, RAID 6 oder einen der kombinierten RAID-Level können jedoch eine Menge Arbeit sein. Bei einem Software-RAID kann es schwierig sein, automatisch von einem ausgefallenen Array zu booten. Schließlich hängt die Art und Weise, wie ein Software-RAID durchgeführt wird, vom verwendeten Betriebssystem ab; es ist im Allgemeinen nicht möglich, ein Software-RAID-Array mit einem anderen Betriebssystem neu zu erstellen. Betriebssysteme verwenden in der Regel eher Festplattenpartitionen als ganze Festplatten, um RAID-Arrays zu erstellen.
Hardware-RAID
Ein RAID kann auch mit Hardware erstellt werden. In diesem Fall wird ein spezieller Plattencontroller verwendet; diese Controllerkarte verbirgt die Tatsache, dass sie ein RAID durchführt, vor dem Betriebssystem und dem Benutzer. Die Berechnungen der Prüfsummeninformationen und andere RAID-bezogene Berechnungen werden auf einem speziellen Mikrochip in diesem Controller durchgeführt. Dadurch wird das RAID unabhängig vom Betriebssystem. Das Betriebssystem sieht das RAID nicht, sondern nur eine einzelne Platte. Verschiedene Hersteller führen RAID auf unterschiedliche Weise durch. Das bedeutet, dass ein RAID, das mit einem Hardware-RAID-Controller aufgebaut wurde, nicht von einem anderen RAID-Controller eines anderen Herstellers neu aufgebaut werden kann. Hardware-RAID-Controller sind oft teuer in der Anschaffung.
Hardware-unterstütztes RAID
Dies ist eine Mischung aus Hardware-RAID und Software-RAID. Hardware-unterstütztes RAID verwendet einen speziellen Controller-Chip (wie Hardware-RAID), aber dieser Chip kann nicht viele Operationen durchführen. Er ist nur aktiv, wenn das System gestartet wird; sobald das Betriebssystem vollständig geladen ist, ist diese Konfiguration wie Software-RAID. Einige Hauptplatinen verfügen über RAID-Funktionen für die angeschlossenen Platten; meistens werden diese RAID-Funktionen als hardwaregestütztes RAID ausgeführt. Das bedeutet, dass spezielle Software erforderlich ist, um diese RAID-Funktionen nutzen zu können und um von einer ausgefallenen Platte wiederhergestellt werden zu können.
Unterschiedliche Begriffe im Zusammenhang mit Hardware-Ausfällen
Es gibt verschiedene Begriffe, die verwendet werden, wenn über Hardware-Ausfälle gesprochen wird:
Misserfolgsrate
Die Ausfallrate gibt an, wie oft ein System ausfällt. Die mittlere Zeit bis zum Ausfall (MTTF) oder die mittlere Zeit zwischen Ausfällen (MTBF) eines RAID-Systems ist die gleiche wie die seiner Komponenten. Ein RAID-System kann schließlich nicht vor Ausfällen seiner einzelnen Festplatten schützen. Die komplizierteren RAID-Typen (alles, was über "Striping" oder "Verkettung" hinausgeht) können jedoch dazu beitragen, die Daten intakt zu halten, selbst wenn eine einzelne Festplatte ausfällt.
Mittlere Zeit bis zum Datenverlust
Die mittlere Zeit bis zum Datenverlust (MTTDL) gibt die durchschnittliche Zeit an, bevor ein Datenverlust in einem bestimmten Array auftritt. Die mittlere Zeit bis zum Datenverlust eines gegebenen RAID kann höher oder niedriger sein als die seiner Festplatten. Dies hängt vom Typ des verwendeten RAID ab.
Mittlere Zeit bis zur Genesung
Arrays, die über Redundanz verfügen, können sich von einigen Ausfällen erholen. Die mittlere Zeit bis zur Wiederherstellung zeigt, wie lange es dauert, bis ein ausgefallenes Array wieder in seinen normalen Zustand zurückkehrt. Dadurch erhöht sich sowohl die Zeit für das Ersetzen eines ausgefallenen Plattenmechanismus als auch die Zeit für den Neuaufbau des Arrays (d.h. für die Replikation von Daten für die Redundanz).
Nicht wiederherstellbare Bitfehlerrate
Die Unwiederherstellungs-Bitfehlerrate (UBE) gibt an, wie lange ein Plattenlaufwerk nach der Verwendung von CRC-Codes (CRC = Cyclic Redundancy Check) und mehreren Wiederholungsversuchen nicht in der Lage ist, Daten wiederherzustellen.
Probleme mit RAID
Es gibt auch gewisse Probleme mit den Ideen oder der Technologie hinter RAID:
Hinzufügen von Datenträgern zu einem späteren Zeitpunkt
Bestimmte RAID-Level erlauben die Erweiterung des Arrays durch einfaches Hinzufügen von Festplatten zu einem späteren Zeitpunkt. Informationen wie z.B. Paritätsblöcke sind oft auf mehrere Festplatten verstreut. Das Hinzufügen einer Festplatte zum Array bedeutet, dass eine Reorganisation erforderlich wird. Eine solche Reorganisation ist wie ein Neuaufbau des Arrays, sie kann viel Zeit in Anspruch nehmen. Wenn dies geschehen ist, steht der zusätzliche Speicherplatz möglicherweise noch nicht zur Verfügung, da sowohl das Dateisystem auf dem Array als auch das Betriebssystem darüber informiert werden müssen. Einige Dateisysteme unterstützen es nicht, nach ihrer Erstellung zu wachsen. In einem solchen Fall müssen alle Daten gesichert werden, das Array muss mit dem neuen Layout neu erstellt und die Daten darauf wiederhergestellt werden.
Eine weitere Möglichkeit, Speicher hinzuzufügen, besteht darin, ein neues Array zu erstellen und die Situation von einem logischen Volume-Manager handhaben zu lassen. Auf diese Weise kann fast jedes RAID-System erweitert werden, sogar RAID1 (das an sich auf zwei Platten begrenzt ist).
Verknüpfte Ausfälle
Der Fehlerkorrekturmechanismus im RAID geht davon aus, dass Ausfälle von Laufwerken unabhängig sind. Es ist möglich, zu berechnen, wie oft ein Gerät ausfallen kann, und das Array so anzuordnen, dass ein Datenverlust sehr unwahrscheinlich ist.
In der Praxis wurden die Laufwerke jedoch oft zusammen gekauft. Sie sind ungefähr gleich alt und wurden ähnlich benutzt (man spricht von Verschleiß). Viele Laufwerke fallen aufgrund mechanischer Probleme aus. Je älter ein Laufwerk ist, desto stärker sind seine mechanischen Teile verschlissen. Mechanische Teile, die alt sind, versagen mit größerer Wahrscheinlichkeit als solche, die jünger sind. Das bedeutet, dass Antriebsausfälle statistisch nicht mehr unabhängig sind. In der Praxis besteht die Möglichkeit, dass ein zweiter Datenträger ebenfalls ausfällt, bevor der erste wiederhergestellt wurde. Das bedeutet, dass Datenverluste in der Praxis mit erheblichen Raten auftreten können.
Atomarität
Ein weiteres Problem, das auch bei RAID-Systemen auftritt, ist, dass Anwendungen das erwarten, was als Atomicity bezeichnet wird: Entweder werden alle Daten geschrieben, oder es werden keine geschrieben. Das Schreiben der Daten wird als Transaktion bezeichnet.
In RAID-Arrays werden die neuen Daten normalerweise an die Stelle geschrieben, an der sich die alten Daten befanden. Dies ist als "Update in-place" bekannt geworden. Jim Gray, ein Datenbankforscher, schrieb 1981 einen Aufsatz, in dem er dieses Problem beschrieb.
Nur sehr wenige Speichersysteme erlauben eine atomare Schreibsemantik. Wenn ein Objekt auf die Festplatte geschrieben wird, schreibt ein RAID-Speichergerät normalerweise alle Kopien des Objekts parallel. Sehr oft gibt es nur einen Prozessor, der für das Schreiben der Daten verantwortlich ist. In einem solchen Fall überschneiden sich die Schreibvorgänge der Daten auf die verschiedenen Laufwerke. Dies wird als überlapptes Schreiben oder gestaffeltes Schreiben bezeichnet. Ein Fehler, der während des Schreibvorgangs auftritt, kann daher dazu führen, dass sich die redundanten Kopien in unterschiedlichen Zuständen befinden. Was noch schlimmer ist, es kann dazu führen, dass sich die Kopien weder im alten noch im neuen Zustand befinden. Die Protokollierung setzt allerdings voraus, dass sich die Originaldaten entweder im alten oder im neuen Zustand befinden. Dadurch kann die logische Änderung rückgängig gemacht werden, aber nur wenige Speichersysteme bieten eine atomare Schreibsemantik auf einer RAID-Platte.
Die Verwendung eines batteriegepufferten Schreibcaches kann dieses Problem lösen, aber nur in einem Stromausfall-Szenario.
Transaktionsunterstützung ist nicht in allen Hardware-RAID-Controllern vorhanden. Daher ist sie in vielen Betriebssystemen zum Schutz vor Datenverlust während eines unterbrochenen Schreibvorgangs enthalten. Novell Netware enthielt ab Version 3.x ein Transaktionsverfolgungssystem. Microsoft führte die Transaktionsverfolgung über die Journalfunktion in NTFS ein. Das WAFL-Dateisystem von NetApp löst dieses Problem, indem es die vorhandenen Daten nie aktualisiert, ebenso wie ZFS.
Nicht wiederherstellbare Daten
Einige Sektoren auf einer Festplatte können durch einen Fehler unlesbar geworden sein. Einige RAID-Implementierungen können mit dieser Situation umgehen, indem sie die Daten an einen anderen Ort verschieben und den Sektor auf der Platte als schlecht markieren. Dies geschieht bei etwa 1 Bit in 1015 bei Plattenlaufwerken der Unternehmensklasse und 1 Bit in 1014 bei gewöhnlichen Plattenlaufwerken. Die Plattenkapazitäten nehmen ständig zu. Dies kann dazu führen, dass ein RAID manchmal nicht wieder aufgebaut werden kann, weil ein solcher Fehler gefunden wird, wenn das Array nach einem Plattenfehler wieder aufgebaut wird. Bestimmte Technologien wie RAID 6 versuchen, dieses Problem zu lösen, aber sie leiden unter einer sehr hohen Schreibstrafe, d.h. das Schreiben von Daten wird sehr langsam.
Schreib-Cache-Zuverlässigkeit
Das Plattensystem kann den Schreibvorgang bestätigen, sobald sich die Daten im Cache befinden. Es braucht nicht zu warten, bis die Daten physisch geschrieben wurden. Ein Stromausfall kann dann jedoch einen erheblichen Datenverlust der in einem solchen Cache anstehenden Daten bedeuten.
Bei Hardware-RAID kann eine Batterie verwendet werden, um diesen Cache zu schützen. Dadurch wird das Problem oft gelöst. Wenn die Stromversorgung ausfällt, kann der Controller den Cache zu Ende schreiben, wenn die Stromversorgung wieder hergestellt ist. Diese Lösung kann jedoch immer noch fehlschlagen: die Batterie kann abgenutzt sein, der Strom kann zu lange abgeschaltet gewesen sein, die Platten können auf einen anderen Controller verschoben werden, der Controller selbst kann ausfallen. Bestimmte Systeme können regelmäßige Batterieüberprüfungen durchführen, aber diese verwenden die Batterie selbst und lassen sie in einem Zustand, in dem sie nicht vollständig geladen ist.
Kompatibilität der Ausrüstung
Die Plattenformate auf verschiedenen RAID-Controllern sind nicht unbedingt kompatibel. Daher ist es möglicherweise nicht möglich, ein RAID-Array auf unterschiedlicher Hardware zu lesen. Folglich kann es bei einem Ausfall der Nicht-Festplatten-Hardware erforderlich sein, identische Hardware oder ein Backup zur Wiederherstellung der Daten zu verwenden.
Was RAID kann und was nicht
Dieser Leitfaden wurde aus einem Thread in einem RAID-bezogenen Forum entnommen. Er wurde erstellt, um die Vor- und Nachteile der Wahl von RAID aufzuzeigen. Er richtet sich an Personen, die RAID entweder zur Leistungssteigerung oder zur Redundanz wählen möchten. Er enthält Links zu anderen Threads in seinem Forum, die von Benutzern erstellte anekdotische Berichte über ihre RAID-Erfahrungen enthalten.
Was RAID leisten kann
- RAID kann die Betriebszeit schützen. RAID-Level 1, 0+1/10, 5 und 6 (und ihre Varianten wie 50 und 51) gleichen einen mechanischen Festplattenausfall aus. Auch nach dem Ausfall der Festplatte können die Daten auf dem Array weiterhin verwendet werden. Anstelle einer zeitaufwändigen Wiederherstellung von Band, DVD oder anderen langsamen Sicherungsmedien ermöglicht RAID die Wiederherstellung von Daten von den anderen Mitgliedern des Arrays auf eine Ersatzplatte. Während dieses Wiederherstellungsprozesses steht es den Benutzern in einem degradierten Zustand zur Verfügung. Dies ist für Unternehmen sehr wichtig, da Ausfallzeiten schnell zu einem Verlust der Ertragskraft führen. Für Privatanwender kann es die Betriebszeit von großen Medienspeicher-Arrays schützen, die bei einem Ausfall einer nicht durch Redundanz geschützten Platte eine zeitaufwändige Wiederherstellung von Dutzenden von DVDs oder ziemlich vielen Bändern erfordern würde.
- RAID kann die Leistung bei bestimmten Anwendungen erhöhen. Die RAID-Level 0, 5 und 6 verwenden alle Striping. Dadurch können mehrere Spindeln die Übertragungsraten für lineare Übertragungen erhöhen. Workstation-artige Anwendungen arbeiten oft mit großen Dateien. Sie profitieren in hohem Maße vom Festplatten-Striping. Beispiele für solche Anwendungen sind Anwendungen, die Video- oder Audiodateien verwenden. Dieser Durchsatz ist auch bei Datensicherungen von Platte zu Platte nützlich. Sowohl RAID 1 als auch andere Striping-basierte RAID-Level können die Leistung für Zugriffsmuster mit vielen gleichzeitigen wahlfreien Zugriffen, wie sie von einer Mehrbenutzer-Datenbank verwendet werden, verbessern.
Was RAID nicht kann
- RAID kann die Daten auf dem Array nicht schützen. Ein RAID-Array hat ein Dateisystem. Dadurch entsteht ein einziger Fehlerpunkt. Es gibt viele Dinge, die mit diesem Dateisystem außer einem physischen Plattenfehler passieren können. RAID kann diese Quellen von Datenverlusten nicht abwehren. RAID kann einen Virus nicht daran hindern, Daten zu zerstören. RAID kann eine Beschädigung nicht verhindern. RAID wird keine Daten speichern, wenn ein Benutzer sie verändert oder versehentlich löscht. RAID schützt Daten nicht vor Hardware-Ausfällen von Komponenten außer physischen Festplatten. RAID schützt Daten nicht vor Naturkatastrophen oder von Menschen verursachten Katastrophen wie Bränden und Überschwemmungen. Um Daten zu schützen, müssen sie auf Wechselmedien wie DVD, Band oder einer externen Festplatte gesichert werden. Die Sicherung muss an einem anderen Ort aufbewahrt werden. RAID allein kann nicht verhindern, dass eine Katastrophe, wenn (nicht falls) sie eintritt, zu einem Datenverlust wird. Katastrophen lassen sich nicht verhindern, aber durch Backups kann ein Datenverlust verhindert werden.
- RAID kann die Notfallwiederherstellung nicht vereinfachen. Wenn eine einzelne Festplatte ausgeführt wird, kann die Festplatte von den meisten Betriebssystemen verwendet werden, da sie mit einem gemeinsamen Gerätetreiber ausgestattet sind. Die meisten RAID-Controller benötigen jedoch spezielle Treiber. Wiederherstellungstools, die mit einzelnen Platten auf generischen Controllern arbeiten, erfordern spezielle Treiber für den Zugriff auf Daten auf RAID-Arrays. Wenn diese Wiederherstellungstools schlecht kodiert sind und die Bereitstellung zusätzlicher Treiber nicht erlauben, ist ein RAID-Array für dieses Wiederherstellungstool wahrscheinlich unzugänglich.
- RAID kann nicht bei allen Anwendungen eine Leistungssteigerung bewirken. Diese Aussage trifft insbesondere auf typische Benutzer von Desktop-Anwendungen und Gamer zu. Für die meisten Desktop-Anwendungen und Spiele sind die Pufferstrategie und die angestrebte Leistung der Platte(n) wichtiger als der Rohdurchsatz. Eine Erhöhung der anhaltenden Rohdaten-Übertragungsrate bringt für solche Benutzer nur geringe Vorteile, da die meisten Dateien, auf die sie zugreifen, in der Regel ohnehin sehr klein sind. Platten-Striping mit RAID 0 erhöht die lineare Übertragungsleistung, nicht die Puffer- und Suchleistung. Infolgedessen zeigt das Festplatten-Striping mit RAID 0 bei den meisten Desktop-Anwendungen und Spielen nur geringe bis gar keine Leistungssteigerung, obwohl es Ausnahmen gibt. Für Desktop-Benutzer und Spieler, die hohe Leistung als Ziel haben, ist es besser, eine schnellere, größere und teurere einzelne Platte zu kaufen, als zwei langsamere/kleinere Laufwerke in RAID 0 zu betreiben. Selbst beim Betrieb der neuesten, größten und größten Laufwerke in RAID-0 ist es unwahrscheinlich, dass die Leistung um mehr als 10 % gesteigert wird, und die Leistung kann bei einigen Zugriffsmustern, insbesondere bei Spielen, sinken.
- Es ist schwierig, RAID auf ein neues System umzustellen. Mit einer einzelnen Platte ist es relativ einfach, die Platte auf ein neues System zu verschieben. Sie kann einfach an das neue System angeschlossen werden, wenn es die gleiche Schnittstelle zur Verfügung hat. Bei einem RAID-Array ist dies jedoch nicht so einfach. Es gibt eine bestimmte Art von Metadaten, die angeben, wie der RAID-Verbund aufgebaut ist. Ein RAID-BIOS muss in der Lage sein, diese Metadaten zu lesen, damit es das Array erfolgreich aufbauen und für ein Betriebssystem zugänglich machen kann. Da die Hersteller von RAID-Controllern unterschiedliche Formate für ihre Metadaten verwenden (sogar Controller verschiedener Familien desselben Herstellers können inkompatible Metadatenformate verwenden), ist es fast unmöglich, ein RAID-Array auf einen anderen Controller zu verschieben. Wenn ein RAID-Array auf ein neues System verschoben wird, sollte geplant werden, auch den Controller zu verschieben. Angesichts der Beliebtheit von Motherboard-integrierten RAID-Controllern ist dies äußerst schwierig. Im Allgemeinen ist es möglich, die Mitglieder des RAID-Arrays und die Controller zusammen zu verschieben. Software-RAID in Linux- und Windows-Server-Produkten kann diese Einschränkung ebenfalls umgehen, aber Software-RAID hat andere (meist leistungsbezogene) Möglichkeiten.
Beispiel
Die am häufigsten verwendeten RAID-Level sind RAID 0, RAID 1 und RAID 5. Angenommen, es handelt sich um einen Aufbau mit 3 identischen Platten von jeweils 1 TB, und die Ausfallwahrscheinlichkeit eines Laufwerks für eine bestimmte Zeitspanne beträgt 1%.
| RAID-Level | Nutzbare Kapazität | Wahrscheinlichkeit des Scheiterns angegeben in Prozent | Wahrscheinlichkeit des Scheiterns 1 in ... Fällen scheitern |
| 0 | 3 TB | 2,9701% | 34 |
| 1 | 1 TB | 0,0001% | 1 Million |
| 5 | 2 TB | 0,0298% | 3356 |
Autor
AlegsaOnline.com RAID Leandro Alegsa
URL: https://de.alegsaonline.com/art/80859
Quellen
- www-2.cs.cmu.edu : ""A Case for Redundant Arrays of Inexpensive Disks" - Patterson, Gibson, Katz"
- thomason.org : "RAID: High-Performance, Reliable Secondary Storage"
- baarf.com : "BAARF - Battle Against Any Raid Five"
- media.netapp.com : "RAID-DP™: Network Appliance™ implementation of RAID Double Parity for data protection, a high speed implementation of RAID 6"
- nasi.com : "IBM X-Architecture Technology 2001:A design blueprint for Intel processor-based servers"
- pcguide.com : "RAID Level 7"
- cgi.cse.unsw.edu.au : "Linux RAID 10 driver"
- linux-raid.osdl.org : "Main Page - Linux-raid"
- blogs.sun.com : "RAID-Z : Jeff Bonwick's Blog"
- blogs.sun.com : "Adam Leventhal's Weblog"
- research.microsoft.com : "Empirical Measurements of Disk Failure Rates and Error Rates"
- usenix.org : "Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You?"
- research.microsoft.com : "The Transaction Concept: Virtues and Limitations (Invited Paper)¦format=pdf"
- informatik.uni-trier.de : "VLDB 1981"
- arxiv.org : "Empirical Measurements of Disk Failure Rates and Error Rates"