DNA (Desoxyribonukleinsäure): Aufbau, Funktion und Vererbung
DNA (Desoxyribonukleinsäure): Aufbau, Funktion & Vererbung verständlich erklärt — Genstruktur, Proteinsynthese, nicht‑kodierende DNA und wie Gene an Nachkommen weitergegeben werden.
DNA, kurz für Desoxyribonukleinsäure, ist das Molekül, das den genetischen Code von Organismen enthält. Dazu gehören Tiere, Pflanzen, Protisten, Archaeen und Bakterien.
Die DNA befindet sich in jeder Zelle des Organismus und sagt den Zellen, welche Proteine sie herstellen sollen. Meistens sind diese Proteine Enzyme. Die DNA wird den Kindern von ihren Eltern vererbt. Aus diesem Grund teilen Kinder Eigenschaften mit ihren Eltern, wie Haut-, Haar- und Augenfarbe. Die DNA in einer Person ist eine Kombination der DNA von jedem ihrer Eltern.
Ein Teil der DNA eines Organismus sind "nicht-kodierende DNA"-Sequenzen. Sie kodieren nicht für Proteinsequenzen. Einige nicht-kodierende DNA wird in nicht-kodierende RNA-Moleküle transkribiert, wie z.B. Transfer-RNA, ribosomale RNA und regulatorische RNAs. Andere Sequenzen werden überhaupt nicht transkribiert oder führen zu RNA mit unbekannter Funktion. Die Menge an nicht-kodierender DNA variiert stark von Spezies zu Spezies. Zum Beispiel sind über 98% des menschlichen Genoms nicht-kodierende DNA, während nur etwa 2% eines typischen bakteriellen Genoms nicht-kodierende DNA ist.
Viren verwenden entweder DNA oder RNA, um Organismen zu infizieren. Die Genomreplikation der meisten DNA-Viren findet im Zellkern statt, während sich RNA-Viren gewöhnlich im Zytoplasma replizieren.
Bildergalerie
10 Bilder






Aufbau der DNA
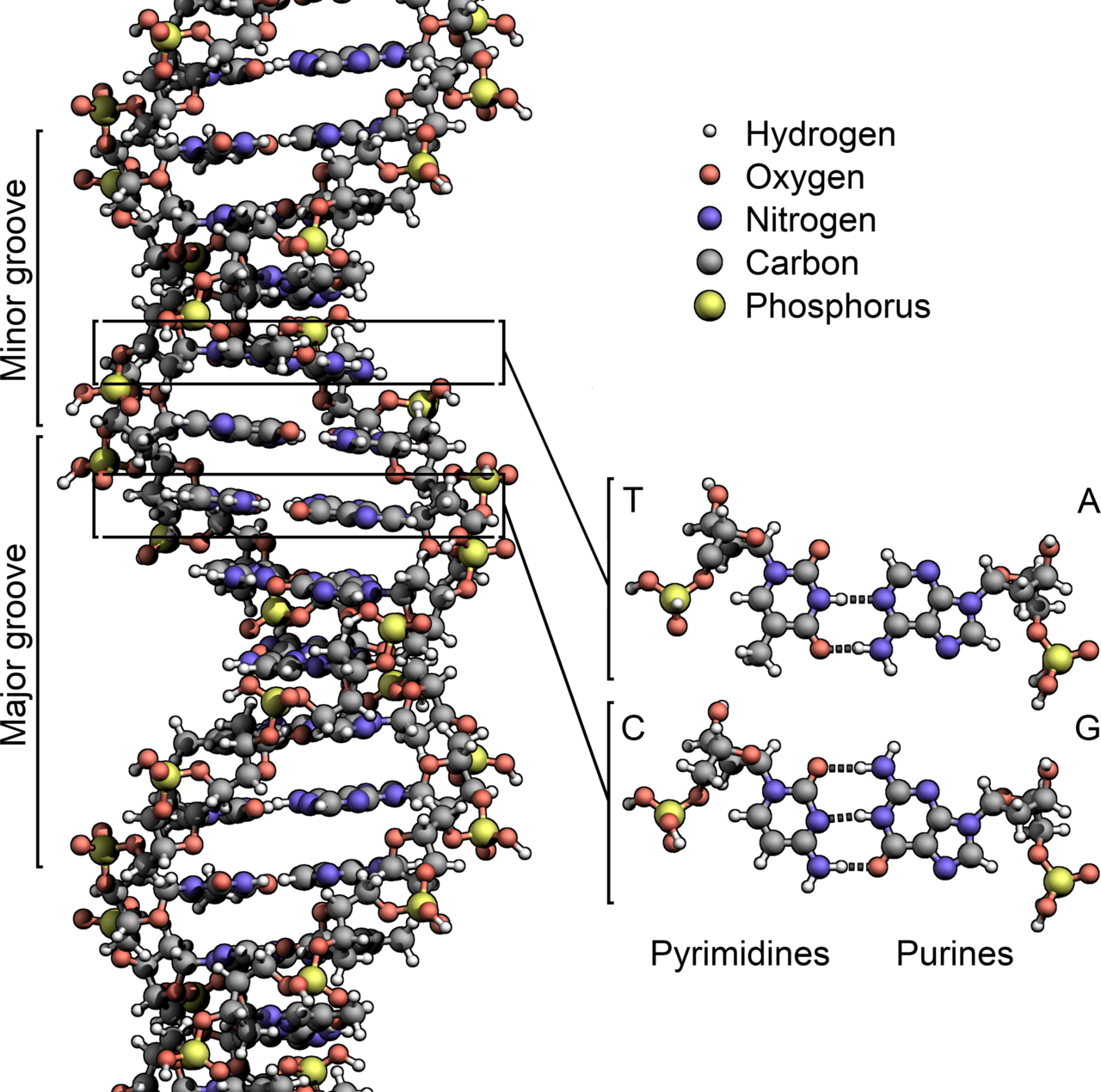
DNA ist ein langes Polymer aus wiederholenden Bausteinen, den Nukleotiden. Jedes Nukleotid besteht aus drei Teilen: einem Phosphatrest, einem Zucker (Desoxyribose) und einer stickstoffhaltigen Base. Es gibt vier Basen in der DNA: Adenin (A), Thymin (T), Cytosin (C) und Guanin (G). Zwei DNA-Stränge laufen antiparallel und bilden zusammen die bekannte Doppelhelix. Die beiden Stränge werden durch Wasserstoffbrücken zwischen den Basen zusammengehalten: A paart mit T über zwei Wasserstoffbrücken, C paart mit G über drei Wasserstoffbrücken.
In eukaryotischen Zellen ist DNA linear organisiert und eng mit Proteinen (Histonen) zu Chromatin und Chromosomen verpackt. Diese Verpackung reguliert den Zugang von Enzymen zur DNA. Prokaryoten haben meist zirkuläre DNA-Moleküle und können zusätzliche zirkuläre Plasmide tragen, die Gene für Antibiotikaresistenz oder Stoffwechselwege enthalten. Außerdem besitzen viele Zellen organell-spezifische Genome, z.B. mitochondriale DNA bei Tieren und mitochondriale sowie chloroplastäre DNA bei Pflanzen.
Funktion der DNA
Die Hauptfunktion der DNA ist die Speicherung und Übertragung von biologischer Information. Gene sind Abschnitte der DNA, die Informationen für die Herstellung von RNA und meist für Proteine enthalten. Diese Proteine übernehmen strukturelle Aufgaben, wirken als Enzyme oder regulieren zelluläre Prozesse. Neben codierenden Genen enthält das Genom zahlreiche regulatorische Sequenzen (Promotoren, Enhancer), strukturelle Elemente (z.B. Telomere) und repetitive Abschnitte.
Replikation, Transkription und Translation
Vor jeder Zellteilung muss die DNA vervielfältigt werden. Die Replikation ist semikonservativ: jeder Tochterstrang erhält einen alten und einen neu synthetisierten Strang. DNA-Polymerasen fügen Nukleotide am 3'-Ende hinzu; die Synthese erfolgt kontinuierlich am Leitstrang und stapelweise als kurze Okazaki-Fragmente am Folgestrang.
Bei der Transkription wird ein Gen in eine RNA-Kopie (mRNA) abgeschrieben. In Eukaryoten wird die prä-mRNA oft prozessiert: Spleißen (Entfernen von Introns), Anfügen einer 5'-Kappe und eines 3'-Poly(A)-Schwanzes. Die mRNA wird dann im Zytoplasma von Ribosomen in Aminosäureketten übersetzt – der Prozess heißt Translation. Drei Basen (Codon) der mRNA codieren für eine Aminosäure; dieses System bildet den genetischen Code.
Nicht-kodierende DNA und Genregulation
Nicht-kodierende DNA umfasst viele funktionelle Elemente: Promotoren, Enhancer, Silencer, Insulatoren sowie Gene für nicht-kodierende RNAs (z. B. microRNAs, long non-coding RNAs). Außerdem gehören repetitive Elemente und Transposons dazu, die das Genom dynamisch verändern können. Nicht-kodierende Regionen spielen eine zentrale Rolle bei der Regulation der Genaktivität, der Chromatinstruktur und der evolutionären Anpassung.
Mutationen, Reparatur und epigenetische Regulation
Mutationen sind Veränderungen in der DNA-Sequenz. Sie können spontan auftreten oder durch Umwelteinflüsse (Strahlung, Chemikalien) verursacht werden. Typen von Mutationen sind Basenaustausch (punktuelle Mutationen), Einfügungen, Deletionen und größere strukturelle Veränderungen. Folgen reichen von neutral über schädlich bis zu vorteilhaft. Zellen besitzen Reparatursysteme (z. B. Basenexzisionsreparatur, Nukleotidexzisionsreparatur), die Fehler erkennen und beheben.
Epigenetische Modifikationen (z. B. DNA-Methylierung, Histonmodifikationen) verändern die Genexpression, ohne die DNA-Sequenz zu verändern. Manche epigenetische Zustände können über Zellteilungen hinweg stabil bleiben und damit phänotypische Effekte beeinflussen.
Vererbung und genetische Variation
Vererbung beruht auf der Übertragung von DNA durch Gameten (Eizelle, Spermium). Während der Meiose werden Chromosomen neu assortiert und durch Crossing-over rekombiniert, was genetische Vielfalt schafft. Klassische Muster der Vererbung (Mendel) beschreiben dominante und rezessive Merkmale; daneben gibt es komplexe Vererbungsformen wie polygenetische Traits, unvollständige Dominanz, Kodominanz und mitochondriale Vererbung (maternal).
Genetische Variation entsteht durch Mutationen, Rekombination und Genfluss zwischen Populationen. Diese Variation ist die Grundlage der Evolution und beeinflusst Anfälligkeiten für Krankheiten sowie Merkmale wie Hautfarbe oder Körpergröße.
Unterschiede zwischen Organismen und Viren
Die Menge und Organisation der DNA variiert stark: Bakterielle Genome sind meist kompakt und überwiegend kodierend, während eukaryotische Genome oft viel nicht-kodierende DNA enthalten. Viren können entweder DNA oder RNA als genetisches Material verwenden; einige Viren tragen ihr Genom als doppelsträngige DNA, andere als einzelsträngige RNA. Wie bereits erwähnt, replizieren sich viele DNA-Viren im Zellkern, RNA-Viren hingegen häufig im Zytoplasma. Retroviren nutzen Reverse Transkriptase, um RNA in DNA umzuschreiben und dieses in das Wirtsgenom zu integrieren.
Praktische Anwendungen
- Diagnostik: Gentests, prädiktive Tests, Tumorgenetik und Infektionsdiagnostik.
- Forensik: DNA-Profiling zur Identifikation von Personen.
- Biotechnologie: Gentechnik, rekombinante Proteine, Impfstoffentwicklung, CRISPR/Cas-Genomeditierung.
- Medizin: Gentherapie, personalisierte Medizin auf Basis genetischer Varianten.
- Forschung: Sequenzierung ganzer Genome (z. B. Human Genome Project) liefert Einblicke in Evolution, Krankheit und Biodiversität.
Zusammenfassung
DNA ist das zentrale Informationsmolekül des Lebens. Ihre Struktur, Organisation und dynamische Nutzung ermöglichen die Speicherung, Weitergabe und Umsetzung genetischer Information in Form von Proteinen und regulativen Molekülen. Unterschiede in der DNA erklären die Vielfalt des Lebens, bestimmen Krankheitsrisiken und bieten zahlreiche Anwendungsmöglichkeiten in Wissenschaft, Medizin und Technik.



Struktur der DNA
Die DNA hat die Form einer Doppelhelix, die wie eine spiralförmig gewundene Leiter aussieht. Jede Stufe der Leiter ist ein Nukleotidpaar.
Nukleotide
Ein Nukleotid ist ein Molekül, aus dem ein Molekül besteht:
- Desoxyribose, eine Art Zucker mit 5 Kohlenstoffatomen,
- eine Phosphatgruppe, die aus Phosphor und Sauerstoff besteht, und
- stickstoffhaltige Basis
Die DNA besteht aus vier Arten von Nukleotiden:
- Adenin (A)
- Thymin (T)
- Cytosin (C)
- Guanin (G)
Die "Sprossen" der DNA-Leiter bestehen jeweils aus zwei Basen, wobei von jedem Bein eine Basis ausgeht. Die Basen verbinden sich in der Mitte: 'A' paart nur mit 'T' und 'C' nur mit 'G'. Die Basen werden durch Wasserstoffbrückenbindungen zusammengehalten.
Adenin (A) und Thymin (T) können sich paarweise verbinden, da sie zwei Wasserstoffbrückenbindungen bilden, und Cytosin (C) und Guanin (G) können sich zu drei Wasserstoffbrückenbindungen verbinden. Obwohl die Basen immer in festen Paaren vorliegen, können die Paare in beliebiger Reihenfolge auftreten (A-T oder T-A; ähnlich wie C-G oder G-C). Auf diese Weise kann die DNA aus den "Buchstaben", die die Basen darstellen, "Codes" schreiben. Diese Codes enthalten die Botschaft, die der Zelle sagt, was sie zu tun hat.
Chromatin
Auf den Chromosomen ist die DNA mit Proteinen, den so genannten Histonen, zu Chromatin gebunden. Diese Verbindung ist an der Epigenetik und der Genregulation beteiligt. Gene werden während der Entwicklung und der Zellaktivität an- und abgeschaltet, und diese Regulation ist die Grundlage für den größten Teil der Aktivität, die in den Zellen stattfindet.
Struktur der DNA
Die DNA hat die Form einer Doppelhelix, die wie eine spiralförmig gewundene Leiter aussieht. Jede Stufe der Leiter ist ein Nukleotidpaar.
Nukleotide
Ein Nukleotid ist ein Molekül, aus dem ein Molekül besteht:
- Desoxyribose, eine Art Zucker mit 5 Kohlenstoffatomen,
- eine Phosphatgruppe, die aus Phosphor und Sauerstoff besteht, und
- stickstoffhaltige Basis
Die DNA besteht aus vier Arten von Nukleotiden:
- Adenin (A)
- Thymin (T)
- Cytosin (C)
- Guanin (G)
Die "Sprossen" der DNA-Leiter bestehen jeweils aus zwei Basen, wobei von jedem Bein eine Basis ausgeht. Die Basen verbinden sich in der Mitte: 'A' paart nur mit 'T' und 'C' nur mit 'G'. Die Basen werden durch Wasserstoffbrückenbindungen zusammengehalten.
Adenin (A) und Thymin (T) können sich paarweise verbinden, da sie zwei Wasserstoffbrückenbindungen bilden, und Cytosin (C) und Guanin (G) können sich zu drei Wasserstoffbrückenbindungen verbinden. Obwohl die Basen immer in festen Paaren vorliegen, können die Paare in beliebiger Reihenfolge auftreten (A-T oder T-A; ähnlich wie C-G oder G-C). Auf diese Weise kann die DNA aus den "Buchstaben", die die Basen darstellen, "Codes" schreiben. Diese Codes enthalten die Botschaft, die der Zelle sagt, was sie zu tun hat.
Chromatin
Auf den Chromosomen ist die DNA mit Proteinen, den so genannten Histonen, zu Chromatin gebunden. Diese Verbindung ist an der Epigenetik und der Genregulation beteiligt. Gene werden während der Entwicklung und der Zellaktivität an- und abgeschaltet, und diese Regulation ist die Grundlage für den größten Teil der Aktivität, die in den Zellen stattfindet.
Kopieren von DNA
Wenn DNA kopiert wird, wird dies als DNA-Replikation bezeichnet. Kurz gesagt, die Wasserstoffbrückenbindungen, die gepaarte Basen zusammenhalten, werden gebrochen und das Molekül wird in zwei Hälften gespalten: die Beine der Leiter werden getrennt. Dadurch entstehen zwei Einzelstränge. Neue Stränge werden gebildet, indem die Basen (A mit T und G mit C) zusammengefügt werden, um die fehlenden Stränge zu bilden.
Zunächst spaltet ein Enzym namens DNA-Helikase die DNA durch Aufspaltung der Wasserstoffbrückenbindungen in der Mitte. Dann, nachdem das DNA-Molekül in zwei getrennte Teile zerlegt wurde, bildet ein weiteres Molekül namens DNA-Polymerase einen neuen Strang, der zu jedem der Stränge des gespaltenen DNA-Moleküls passt. Jede Kopie eines DNA-Moleküls besteht zur Hälfte aus dem ursprünglichen (Ausgangs-)Molekül und zur Hälfte aus neuen Basen.
Mutationen
Wenn DNA kopiert wird, werden manchmal Fehler gemacht - diese nennt man Mutationen. Es gibt drei Haupttypen von Mutationen:
- Streichung, bei der eine oder mehrere Basen ausgelassen werden.
- Substitution, bei der eine oder mehrere Basen durch eine oder mehrere andere Basen in der Sequenz ersetzt werden.
- Einfügung, bei der ein oder mehrere zusätzliche Sockel eingesetzt werden.
- Duplikation, bei der eine Folge von Basenpaaren wiederholt wird.
Mutationen können auch nach ihrem Einfluss auf die Struktur und Funktion von Proteinen oder nach ihrem Einfluss auf die Fitness klassifiziert werden. Mutationen können für den Organismus schlecht, neutral oder von Nutzen sein. Manchmal sind Mutationen für den Organismus tödlich - das von der neuen DNA hergestellte Protein funktioniert überhaupt nicht, und das führt zum Absterben des Embryos. Auf der anderen Seite wird die Evolution durch Mutationen vorangetrieben, wenn die neue Version des Proteins besser für den Organismus arbeitet.
Kopieren von DNA
Wenn DNA kopiert wird, wird dies als DNA-Replikation bezeichnet. Kurz gesagt, die Wasserstoffbrückenbindungen, die gepaarte Basen zusammenhalten, werden gebrochen und das Molekül wird in zwei Hälften gespalten: die Beine der Leiter werden getrennt. Dadurch entstehen zwei Einzelstränge. Neue Stränge werden gebildet, indem die Basen (A mit T und G mit C) zusammengefügt werden, um die fehlenden Stränge zu bilden.
Zunächst spaltet ein Enzym namens DNA-Helikase die DNA durch Aufspaltung der Wasserstoffbrückenbindungen in der Mitte. Dann, nachdem das DNA-Molekül in zwei getrennte Teile zerlegt wurde, bildet ein weiteres Molekül namens DNA-Polymerase einen neuen Strang, der zu jedem der Stränge des gespaltenen DNA-Moleküls passt. Jede Kopie eines DNA-Moleküls besteht zur Hälfte aus dem ursprünglichen (Ausgangs-)Molekül und zur Hälfte aus neuen Basen.
Mutationen
Wenn DNA kopiert wird, werden manchmal Fehler gemacht - diese nennt man Mutationen. Es gibt vier Haupttypen von Mutationen:
- Streichung, bei der eine oder mehrere Basen ausgelassen werden.
- Substitution, bei der eine oder mehrere Basen durch eine oder mehrere andere Basen in der Sequenz ersetzt werden.
- Einfügung, bei der ein oder mehrere zusätzliche Sockel eingesetzt werden.
- Duplikation, bei der eine Folge von Basenpaaren wiederholt wird.
Mutationen können auch nach ihrem Einfluss auf die Struktur und Funktion von Proteinen oder nach ihrem Einfluss auf die Fitness klassifiziert werden. Mutationen können für den Organismus schlecht, neutral oder von Nutzen sein. Manchmal sind Mutationen für den Organismus tödlich - das von der neuen DNA hergestellte Protein funktioniert überhaupt nicht, und das führt zum Absterben des Embryos. Auf der anderen Seite wird die Evolution durch Mutationen vorangetrieben, wenn die neue Version des Proteins besser für den Organismus arbeitet.
Protein-Synthese
Ein Abschnitt der DNA, der Anweisungen zur Herstellung eines Proteins enthält, wird als Gen bezeichnet. Jedes Gen hat die Sequenz für mindestens ein Polypeptid. Proteine bilden Strukturen und bilden auch Enzyme. Die Enzyme erledigen die meiste Arbeit in den Zellen. Proteine werden aus kleineren Polypeptiden hergestellt, die aus Aminosäuren gebildet werden. Damit ein Protein eine bestimmte Aufgabe erfüllen kann, müssen die richtigen Aminosäuren in der richtigen Reihenfolge zusammengefügt werden.
Proteine werden von winzigen Maschinen in der Zelle, den so genannten Ribosomen, hergestellt. Die Ribosomen befinden sich im Hauptkörper der Zelle, aber die DNA befindet sich nur im Zellkern. Das Codon ist Teil der DNA, aber die DNA verlässt den Zellkern nie. Da die DNA den Zellkern nicht verlassen kann, macht die Zelle eine Kopie der DNA-Sequenz in der RNA. Diese ist kleiner und kann durch die Löcher - Poren - in der Membran des Zellkerns und in die Zelle hinaus gelangen.
Gene, die in der DNA kodiert sind, werden von Proteinen wie der RNA-Polymerase in Boten-RNA (mRNA) transkribiert. Die reife mRNA wird dann als Vorlage für die Proteinsynthese durch das Ribosom verwendet. Ribosomen lesen Codons, "Wörter", die aus drei Basenpaaren bestehen und dem Ribosom sagen, welche Aminosäure hinzugefügt werden soll. Das Ribosom scannt entlang einer mRNA und liest den Code, während es das Protein herstellt. Eine weitere RNA, tRNA genannt, hilft bei der Zuordnung der richtigen Aminosäure zu jedem Codon.
Protein-Synthese
Ein Abschnitt der DNA, der Anweisungen zur Herstellung eines Proteins enthält, wird als Gen bezeichnet. Jedes Gen hat die Sequenz für mindestens ein Polypeptid. Proteine bilden Strukturen, und sie bilden auch Enzyme. Die Enzyme erledigen die meiste Arbeit in den Zellen. Proteine werden aus kleineren Polypeptiden hergestellt, die aus Aminosäuren gebildet werden. Damit ein Protein eine bestimmte Aufgabe erfüllen kann, müssen die richtigen Aminosäuren in der richtigen Reihenfolge zusammengefügt werden.
Proteine werden von winzigen Maschinen in der Zelle, den so genannten Ribosomen, hergestellt. Die Ribosomen befinden sich im Hauptkörper der Zelle, aber die DNA befindet sich nur im Zellkern. Das Codon ist Teil der DNA, aber die DNA verlässt den Zellkern nie. Da die DNA den Zellkern nicht verlassen kann, macht der Zellkern eine Kopie der DNA-Sequenz in der RNA. Diese ist kleiner und kann durch die Löcher - Poren - in der Membran des Zellkerns und in die Zelle hinaus gelangen.
Gene, die in der DNA kodiert sind, werden von Proteinen wie der RNA-Polymerase in Boten-RNA (mRNA) transkribiert. Die reife mRNA wird dann als Vorlage für die Proteinsynthese durch das Ribosom verwendet. Ribosomen lesen Codons, "Wörter", die aus drei Basenpaaren bestehen und dem Ribosom sagen, welche Aminosäure hinzugefügt werden soll. Das Ribosom scannt entlang einer mRNA und liest den Code, während es das Protein herstellt. Eine weitere RNA, tRNA genannt, hilft bei der Zuordnung der richtigen Aminosäure zu jedem Codon.
Geschichte der DNA-Forschung
DNA wurde erstmals 1869 vom Schweizer Arzt Friedrich Miescher isoliert (aus Zellen extrahiert), als er sich mit Bakterien aus dem Eiter in chirurgischen Verbänden befasste. Das Molekül wurde im Zellkern der Zellen gefunden und deshalb nannte er es Nuclein.
1928 entdeckte Frederick Griffith, dass Merkmale der "glatten" Form von Pneumokokken auf die "raue" Form derselben Bakterien übertragen werden können, indem abgetötete "glatte" Bakterien mit der lebenden "rauen" Form gemischt werden. Dieses System lieferte die erste klare Vermutung, dass die DNA genetische Information trägt.
Das Avery-MacLeod-McCarty-Experiment identifizierte 1943 die DNA als das transformierende Prinzip.
Die Rolle der DNA bei der Vererbung wurde 1952 bestätigt, als Alfred Hershey und Martha Chase im Hershey-Chase-Experiment zeigten, dass die DNA das genetische Material des T2-Bakteriophagen ist.
In den 1950er Jahren stellte Erwin Chargaff fest, dass die Menge an Thymin (T) in einem DNA-Molekül ungefähr der Menge an vorhandenem Adenin (A) entsprach. Er stellte fest, dass dasselbe auch für Guanin (G) und Cytosin (C) gilt. Die Chargaff'sche Regel fasst diesen Befund zusammen.
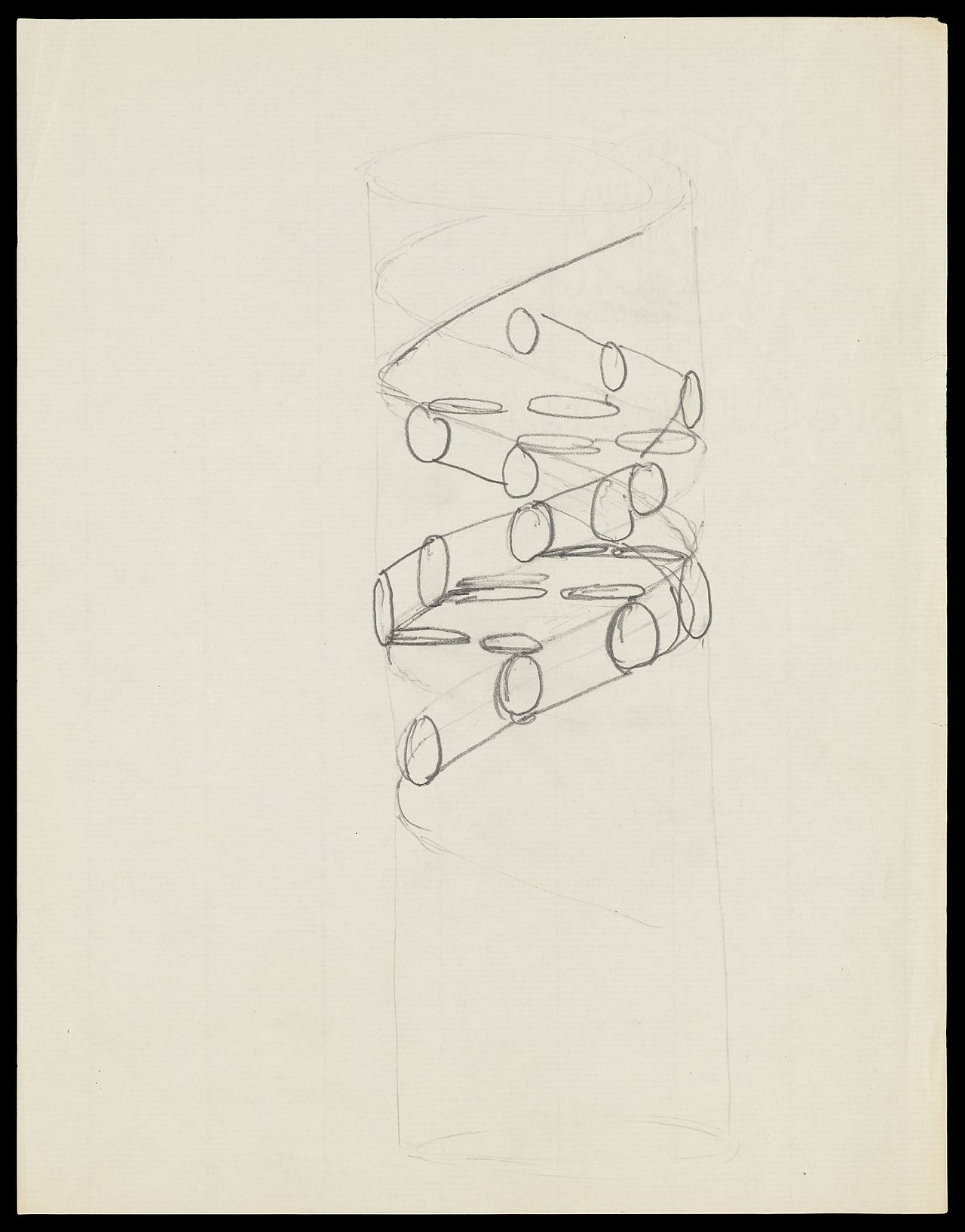
1953 schlugen James D. Watson und Francis Crick in der Zeitschrift Nature das vor, was heute als erstes korrektes Doppelhelixmodell der DNA-Struktur akzeptiert wird. Ihr molekulares Doppelhelixmodell der DNA basierte damals auf einem einzigen Röntgenbeugungsbild "Photo 51", das Rosalind Franklin und Raymond Gosling im Mai 1952 aufgenommen hatten.
Experimentelle Beweise zur Untermauerung des Watson- und Crick-Modells wurden in einer Serie von fünf Artikeln in derselben Ausgabe von Nature veröffentlicht. Von diesen war die Arbeit von Franklin und Gosling die erste Veröffentlichung ihrer eigenen Röntgenbeugungsdaten und ihrer ursprünglichen Analysemethode, die das Watson- und Crick-Modell teilweise unterstützte; diese Ausgabe enthielt auch einen Artikel über die DNA-Struktur von Maurice Wilkins und zwei seiner Kollegen, deren Analyse und in vivo B-DNA-Röntgenmuster ebenfalls das Vorhandensein der Doppelhelix-DNA-Konfigurationen in vivo unterstützten, wie sie von Crick und Watson für ihr molekulares Doppelhelix-Modell der DNA in den beiden vorhergehenden Seiten von Nature vorgeschlagen wurden. 1962, nach Franklins Tod, erhielten Watson, Crick und Wilkins gemeinsam den Nobelpreis für Physiologie oder Medizin. Nobelpreise wurden zu dieser Zeit nur an lebende Empfänger vergeben. Eine Debatte darüber, wer die Anerkennung für die Entdeckung erhalten sollte, geht weiter.
1957 erklärte Crick die Beziehung zwischen DNA, RNA und Proteinen im zentralen Dogma der Molekularbiologie.
Wie die DNA kopiert wurde (der Replikationsmechanismus) kam 1958 durch das Meselson-Stahl-Experiment. Weitere Arbeiten von Crick und Mitarbeitern zeigten, dass der genetische Code auf sich nicht überlappenden Basentripletts, so genannten Codons, basierte. Diese Erkenntnisse stellen die Geburtsstunde der Molekularbiologie dar.
Wie Watson und Crick zu Franklins Ergebnissen kamen, ist viel diskutiert worden. Crick, Watson und Maurice Wilkins erhielten 1962 den Nobelpreis für ihre Arbeit über DNA - Rosalind Franklin war 1958 gestorben.

Geschichte der DNA-Forschung
DNA wurde erstmals 1869 vom Schweizer Arzt Friedrich Miescher isoliert (aus Zellen extrahiert), als er sich mit Bakterien aus dem Eiter in chirurgischen Verbänden befasste. Das Molekül wurde im Zellkern der Zellen gefunden und deshalb nannte er es Nuclein.
1928 entdeckte Frederick Griffith, dass Merkmale der "glatten" Form von Pneumokokken auf die "raue" Form derselben Bakterien übertragen werden können, indem abgetötete "glatte" Bakterien mit der lebenden "rauen" Form gemischt werden. Dieses System lieferte die erste klare Vermutung, dass die DNA genetische Information trägt.
Das Avery-MacLeod-McCarty-Experiment identifizierte 1943 die DNA als das transformierende Prinzip.
Die Rolle der DNA bei der Vererbung wurde 1952 bestätigt, als Alfred Hershey und Martha Chase im Hershey-Chase-Experiment zeigten, dass die DNA das genetische Material des T2-Bakteriophagen ist.
In den 1950er Jahren stellte Erwin Chargaff fest, dass die Menge an Thymin (T) in einem DNA-Molekül ungefähr der Menge an vorhandenem Adenin (A) entsprach. Er stellte fest, dass dasselbe auch für Guanin (G) und Cytosin (C) gilt. Die Chargaff'sche Regel fasst diesen Befund zusammen.
1953 schlugen James D. Watson und Francis Crick in der Zeitschrift Nature das vor, was heute als erstes korrektes Doppelhelixmodell der DNA-Struktur akzeptiert wird. Ihr molekulares Doppelhelixmodell der DNA basierte damals auf einem einzelnen Röntgenbeugungsbild "Photo 51", das Rosalind Franklin und Raymond Gosling im Mai 1952 aufgenommen hatten.
Experimentelle Beweise zur Untermauerung des Watson- und Crick-Modells wurden in einer Serie von fünf Artikeln in derselben Ausgabe von Nature veröffentlicht. Von diesen war die Arbeit von Franklin und Gosling die erste Veröffentlichung ihrer eigenen Röntgenbeugungsdaten und ihrer ursprünglichen Analysemethode, die das Watson- und Crick-Modell teilweise unterstützte; diese Ausgabe enthielt auch einen Artikel über die DNA-Struktur von Maurice Wilkins und zwei seiner Kollegen, deren Analyse und in vivo B-DNA-Röntgenmuster ebenfalls das Vorhandensein der Doppelhelix-DNA-Konfigurationen in vivo unterstützten, wie sie von Crick und Watson für ihr molekulares Doppelhelix-Modell der DNA in den beiden vorhergehenden Seiten von Nature vorgeschlagen wurden. 1962, nach Franklins Tod, erhielten Watson, Crick und Wilkins gemeinsam den Nobelpreis für Physiologie oder Medizin. Nobelpreise wurden zu dieser Zeit nur an lebende Empfänger vergeben. Eine Debatte darüber, wer die Anerkennung für die Entdeckung erhalten sollte, geht weiter.
1957 erklärte Crick die Beziehung zwischen DNA, RNA und Proteinen im zentralen Dogma der Molekularbiologie.
Wie die DNA kopiert wurde (der Replikationsmechanismus) kam 1958 durch das Meselson-Stahl-Experiment. Weitere Arbeiten von Crick und Mitarbeitern zeigten, dass der genetische Code auf sich nicht überlappenden Basentripletts, so genannten Codons, basierte. Diese Erkenntnisse stellen die Geburtsstunde der Molekularbiologie dar.
Wie Watson und Crick zu Franklins Ergebnissen kamen, ist viel diskutiert worden. Crick, Watson und Maurice Wilkins erhielten 1962 den Nobelpreis für ihre Arbeit über DNA - Rosalind Franklin war 1958 gestorben.
DNA- und Datenschutzbedenken
Die Polizei in den Vereinigten Staaten verwendete öffentliche DNA- und Stammbaum-Datenbanken, um ungeklärte Fälle zu lösen. Die American CivilLiberties Union äußerte sich besorgt über diese Praxis.
DNA- und Datenschutzbedenken
Die Polizei in den Vereinigten Staaten verwendete öffentliche DNA- und Stammbaum-Datenbanken, um ungeklärte Fälle zu lösen. Die American Civil Liberties Union äußerte sich besorgt über diese Praxis.
Verwandte Seiten
- Zellteilung
- DNA-Reparatur
- Chromosom
- Sequenz-Analyse
Verwandte Seiten
- Zellteilung
- DNA-Reparatur
- Chromosom
- Sequenz-Analyse
Fragen und Antworten
F: Was ist DNA?
A: DNA steht für Desoxyribonukleinsäure und ist das Molekül, das den genetischen Code von Organismen, einschließlich Tieren, Pflanzen, Protisten, Archaeen und Bakterien enthält. Sie besteht aus zwei Polynukleotidketten in einer Doppelhelix.
F: Wie teilt die DNA den Zellen mit, welche Proteine sie herstellen sollen?
A: Die Proteine, die hergestellt werden, sind meist Enzyme, die durch die in der DNA enthaltenen Anweisungen bestimmt werden.
F: Wie erben Kinder Eigenschaften von ihren Eltern?
A: Kinder teilen Merkmale mit ihren Eltern, weil sie einen Teil der DNA ihrer Eltern erben, die Dinge wie Haut-, Haar- und Augenfarbe bestimmt. Die Kombination aus der DNA beider Elternteile bildet einen einzigartigen Satz von Anweisungen für jedes Kind.
F: Was ist nicht-kodierende DNA?
A: Nicht-codierende DNA-Sequenzen sind Teile des Genoms eines Organismus, die nicht für Proteinsequenzen codieren. Einige nicht-kodierende DNAs können in nicht-kodierende RNA-Moleküle wie Transfer-RNA oder ribosomale RNA umgeschrieben werden, während andere Sequenzen möglicherweise überhaupt nicht umgeschrieben werden oder zu RNAs mit unbekannten Funktionen führen. Die Menge an nicht-kodierender DNA variiert von Art zu Art.
F: Wo speichern eukaryotische Organismen den Großteil ihrer DNA?
A: Eukaryotische Organismen wie Tiere, Pflanzen, Pilze und Protisten speichern den Großteil ihrer DNA im Zellkern, während Prokaryoten wie Bakterien und Archaeen ihre DNA nur im Zytoplasma in zirkulären Chromosomen speichern.
F: Wie hilft das Chromatin bei der Organisation der DNA in den eukaryontischen Chromosomen?
A: Chromatinproteine wie Histone helfen dabei, die DNA in den eukaryotischen Chromosomen zu verdichten und zu organisieren, damit sie bei Bedarf leicht zugänglich ist.
Verwandte Artikel
Autor
AlegsaOnline.com DNA (Desoxyribonukleinsäure): Aufbau, Funktion und Vererbung Leandro Alegsa
URL: https://de.alegsaonline.com/art/28078
Quellen
- cell.com : cell.com/trends/genetics//retrieve/pii/S0168952508001510?_returnURL=http://linkinghub.els…
- doi.org : 10.1146/annurev.micro.112408.134338
- jem.org : "Studies on the chemical nature of the substance inducing transformation of pneumococcal types: induction of transformation by a Desoxyribonucleic Acid fraction isolated from Pneumococcus Type III"
- doi.org : 10.1084/jem.79.2.137
- jgp.org : Independent functions of viral protein and nucleic acid in growth of bacteriophage
- jbc.org : "The separation and quantitative estimation of purines and pyrimidines in minute amounts"
- exploratorium.edu : "A structure for deoxyribose nucleic acid"
- nature.com : Double Helix of DNA: 50 Years
- osulibrary.oregonstate.edu : "Original X-ray diffraction image"
- nobelprize.org : The Nobel Prize in Physiology or Medicine 1962
- biomath.nyu.edu : "The double helix and the 'wronged heroine'"
- doi.org : 10.1038/nature01399
- genome.wellcome.ac.uk : On degenerate templates and the adaptor hypothesis (PDF).
- ncbi.nlm.nih.gov : ncbi.nlm.nih.gov/pmc/articles/PMC528642/?tool=pubmed.html
- nobelprize.org : The Nobel Prize in Physiology or Medicine 1968